Adaptando pipelines Jenkins a GitLab

En fintech.works empezamos a trabajar con la arquitectura de microservicios alrededor del año 2017, y en estos años llevamos a producción varios proyectos basados en esta arquitectura pero siempre limitados por la infraestructura del cliente final, ya que nuestro rol se concentra en el desarrollo antes que la implementación final.
Esta experiencia en arquitecturas heterogéneas tuvo un impacto en nuestros procesos de CI/CD los cuales se adaptaron para ser genéricos, predecibles e implementables en cualquier infraestructura, aunque no muy eficientes.
Esta ineficiencia se hizo notar a la hora de implementar un pipeline sencillo para un cliente que usaba GitLab y necesitaba precisamente mejorar los tiempos de CI/CD de sus otros proyectos. Con este desafío aceptado, implementamos nuestro pipeline tradicional (migrado desde Jenkins a GitLab pipelines) y agregamos las siguientes mejoras:
Antes de entrar en las mejoras aclaramos que todas estas se pueden aplicar de alguna u otra manera al Jenkins, hoy nuestro objetivo es mostrar los cambios que nos facilitaron y agilizaron el proceso de CI/CD usando el GitLab con el permiso de implementar todo el circuito desde cero.
1. Docker in Docker (DinD)
En nuestro pipeline tradicional todos los proceso de construcción estaban de alguna forma atados al worker donde se ejecutaban ya que al ser los jobs pocos y sencillos era suficiente con ingresar directamente por SSH al worker y hacer los cambios necesarios para modificar parámetros y dependencias.
Para mejorar este esquema, optamos por ejecutar todos los jobs del pipeline en contenedores Docker basados en imágenes preconfiguradas con todas las herramientas necesarias y versionados en su propio repositorio de infraestructura. Con este esquema implementado no es necesario conectarse directamente a ningún runner, ya que este descarga automáticamente las imágenes latest conteniendo todas las herramientas y configuraciones necesarias para construir correctamente el proyecto.
A continuación se muestra la diferencia a la hora de definir tools en cada esquema, donde GitLab incluye todos los tools necesarios del pipeline en las imágenes Docker de cada stage.
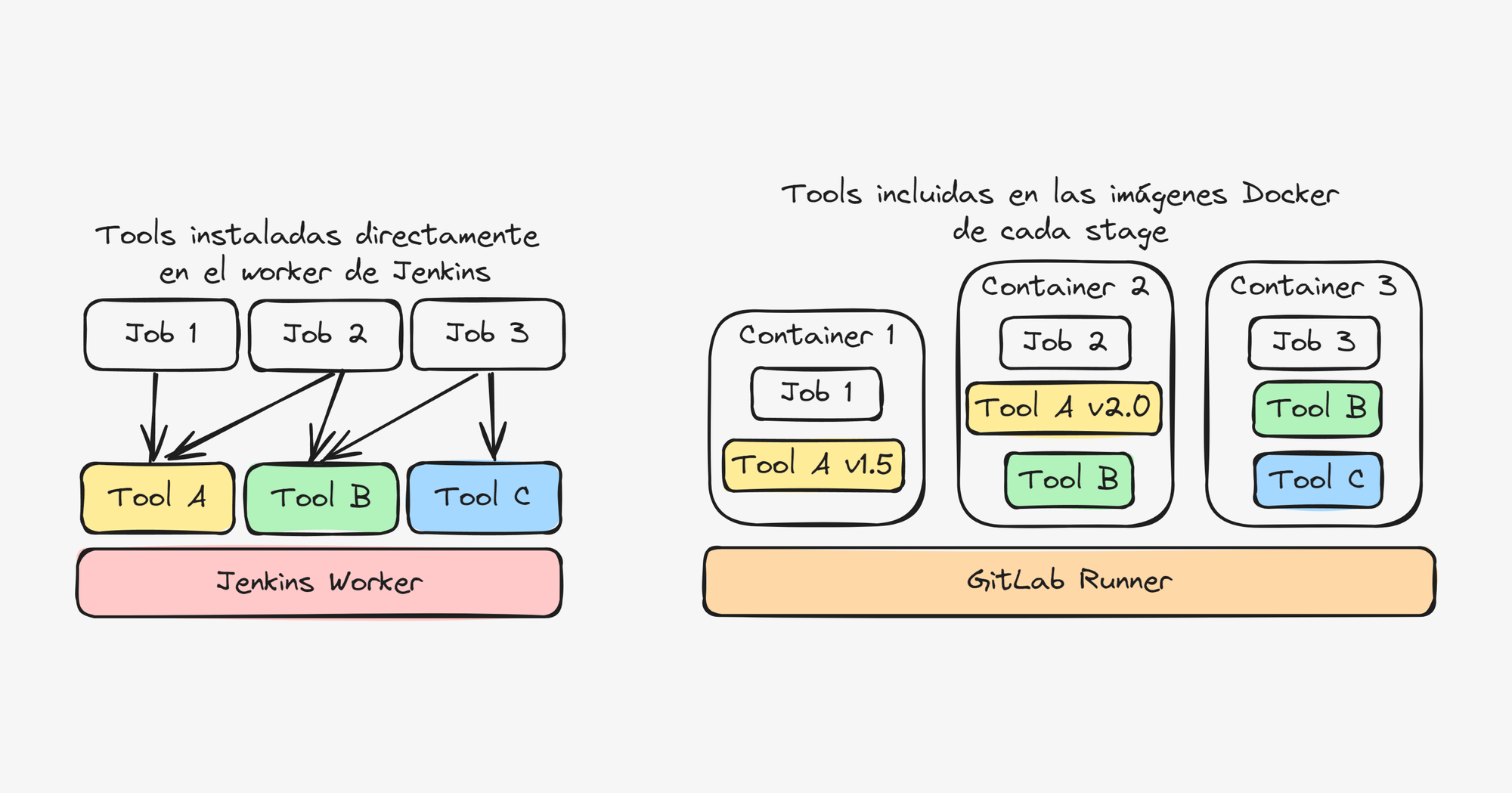
También facilita el proceso de agregar runners heterogéneos (sistemas operativos distintos) ya que el pipeline corre sobre los contenedores Docker.
2. Stages y jobs sencillos
Normalmente nuestros pipelines monorepo estaban compuestos por stages que se encargaban de todo el ciclo de CI/CD de un componente en particular, esto hacía que sean stages grandes y con tareas repetitivas para cada componente y en caso de fallo era necesario recorrer el log para identificar en donde y como ocurrió el fallo.
Para este proyecto se optó por segmentar los pipelines en jobs de acuerdo a la naturaleza del proceso que realiza en vez de separarlos por el componente que construyen, de esta forma logramos que cada job del pipeline haga una sola tarea y pueda ser utilizado en varios stages solo cambiando sus variables de entorno, también este cambio va de la mano con que los jobs sean docker-in-docker ya que de esta forma cada job se basa en una imagen única.
La siguiente imagen muestra la diferencia entre un pipeline Jenkins donde cada job debe tener código para los pasos compile, build, db update y deploy. Mientras que en el esquema de GitLab solo se tiene un conjunto de imágenes Docker que contienen los tools necesarios y el GitLab solo le provee configuraciones para cada pipeline diferente.
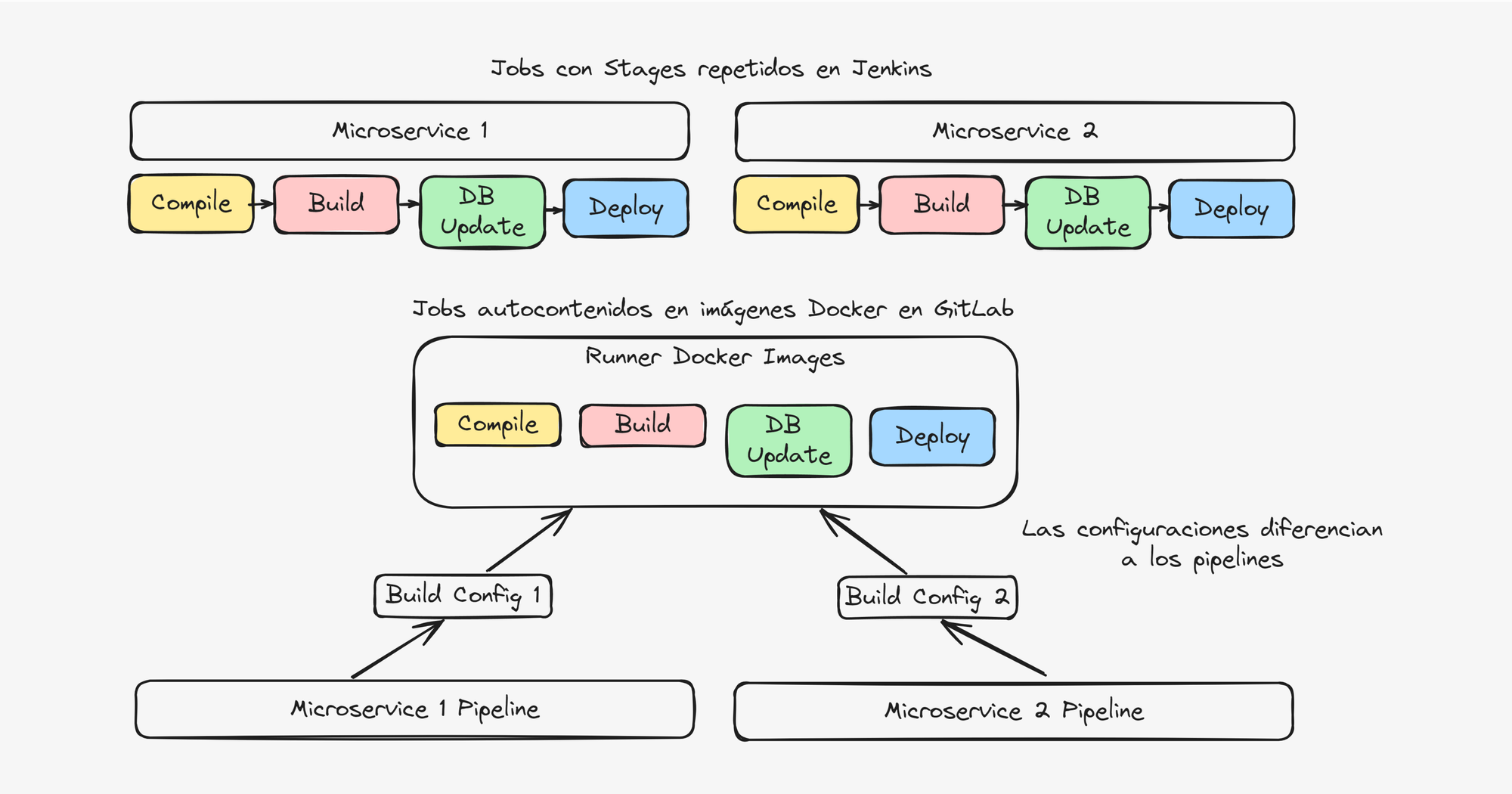
Otros cambios hechos para simplificar los pipelines fueron:
- Utilizar el HASH del commit como versión de las imágenes Docker de cada microservicio, con lo cual el versionado ocurre automáticamente versus tener un mecanismo de SemVer que debe manejar la naturaleza del cambio y luego un esquema de cálculo de versiones en base a esto. Otra razón de elegir este esquema es la velocidad del desarrollo de los componentes los cuales eran construidos varias veces al día.
- Delegar las migraciones de la base de datos a un task ECS: anteriormente la lógica y configuraciones de las migraciones de base de datos residian en el Jenkins, esto hacía necesario que el pipeline contenga información, configuraciones y tiempo de ejecución dedicadas a este paso por más que no siempre era necesario, lo cual mejoramos haciendo que el pipeline solo se limite a invocar la migración de la base de datos ejecutando un task dentro del cluster ECS, este task contiene las herramientas, configuraciones y lógica para llevar a cabo las migraciones dentro del propio cluster. Desde el punto de vista del Jenkins, él solo ejecutó un task en el cluster.
3. Caché vs artefactos
Utilizamos caché en vez artefactos a la hora de compartir archivos, por ejemplo jars, entre jobs, ya que la caché se comparte a nivel del filesystem del runner vs los artefactos que primero deben ser subidos al servidor del GitLab, lo cual hacía que los pipelines tarden más de la cuenta a la hora de subir y bajar artefactos por más que la conexión a internet sea buena.
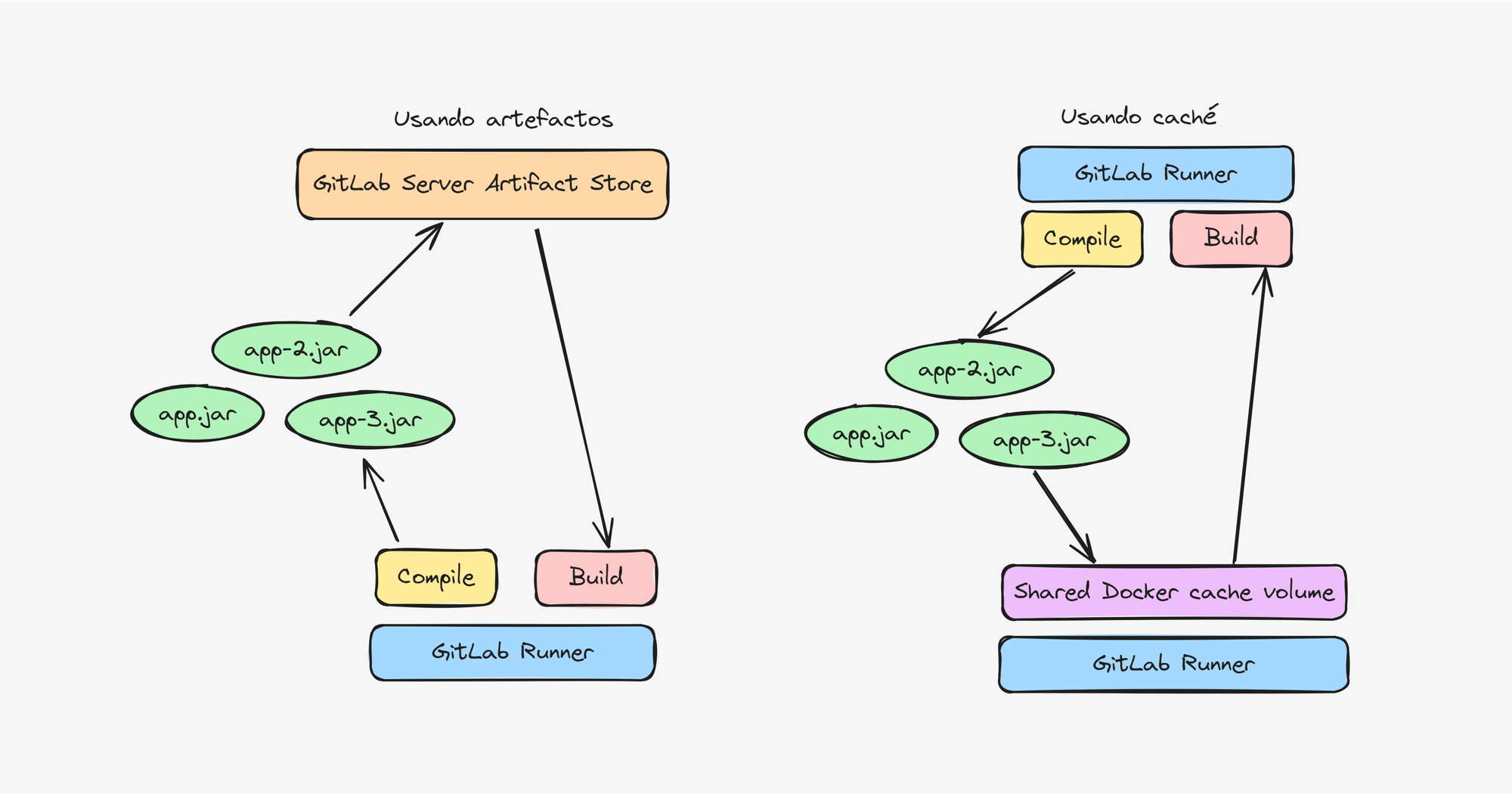
La otra ventaja de la caché es que puede ser configurada como volumen de docker haciendo que la caché persista entre ejecuciones del pipeline acelerando los procesos de construcción por ejemplo gradle assemble que tienen cachés de construcción en directorios bien definidos.
4. Push específico y simultáneo a varios ambientes (para casos específicos)
Nuestro pipeline de CI/CD solo se ejecuta para la rama master, por lo que cada imagen Docker generada corresponde a un commit en esta rama, esta imagen es desplegada automáticamente en el ambiente de desarrollo y en simultáneo se sube a los ECR de los ambientes de QA y producción pero sin desplegarla, con esto se asegura que los ambientes tengan las mismas imágenes, que corresponden a los mismos commits del código, por lo que un pase a QA o producción solo requiere actualizar las versiones en los tasks-definitions.
Aclaramos que tener una sola rama para todos los ambientes no es una práctica recomendada, pero en nuestro caso particular con ciclos de release cortos, nos agiliza el proceso de despliegue.
5. Versión global de plataforma (para casos específicos)
En nuestra experiencia con despliegues de microservicios a QA y Producción nos dimos cuenta que en sistemas altamente dependientes entre sí no es importante mantener una versión individual de cada microservicio ya que en general estos se terminan desplegando juntos al mismo tiempo y que raramente hay cambios que afectan a un solo microservicio.
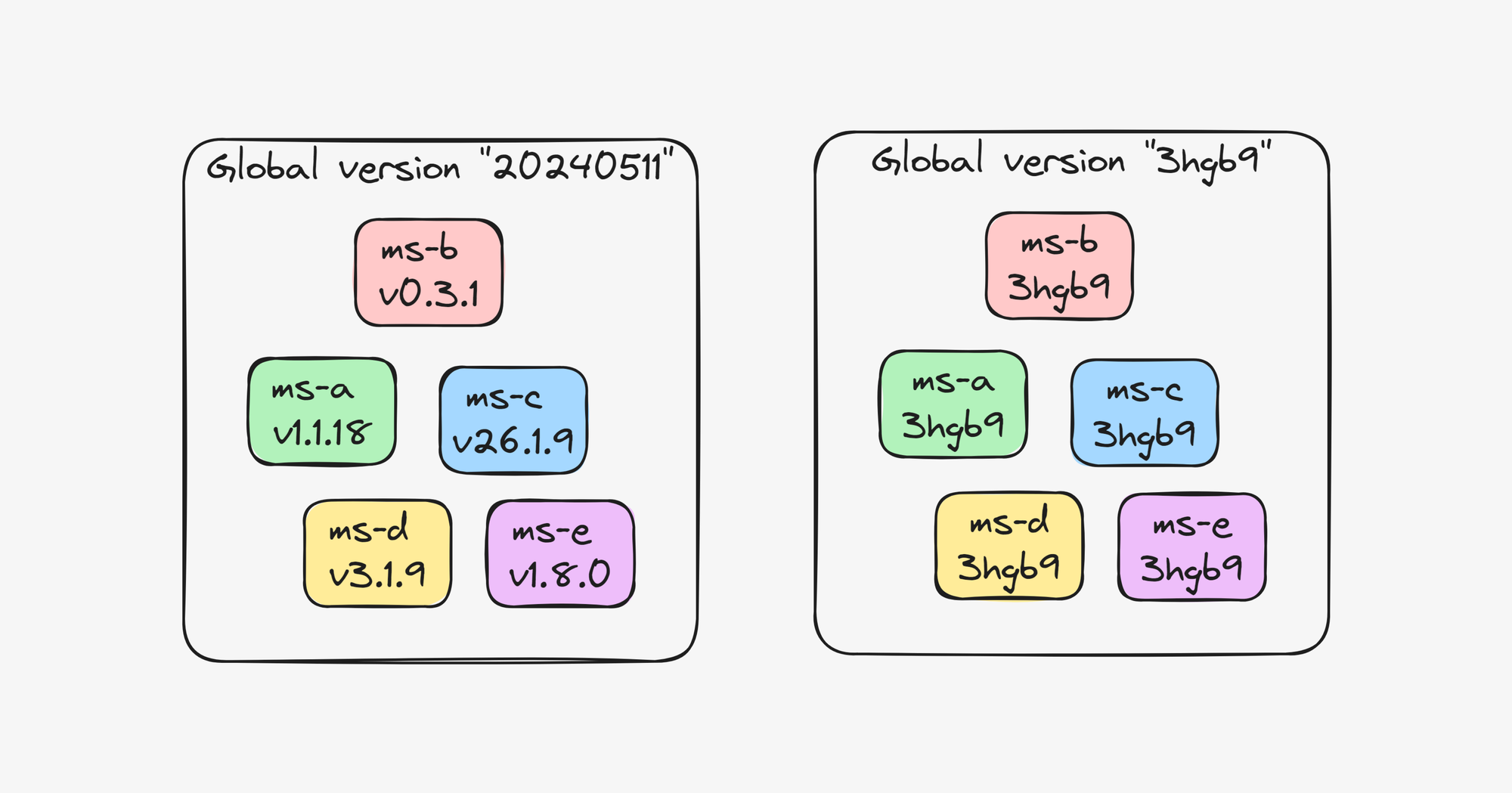
En nuestro caso solo teníamos 2 microservicios grandes asi que decidimos probar el esquema de versiones de commit SHA transversal a todos los microservicios cada vez que un commit es aceptado en la rama master, por ejemplo si solo se modifica el microservicio A, entonces todos los microservicios cambiarán de versión a este commit en particular, lo que hace innecesario mantener un registro de versiones individuales para cada pase a QA, con solo anotar el último commit aceptado para este ambiente, se puede hacer un despliegue.
También como en el punto 3, aclaramos que este esquema de versión global funciona bien para casos donde los microservicios raramente se despliegan de forma independiente, para arquitecturas donde los microservicios se despliegan por separado, es mejor mantener un registro de versiones individual.
¡Suscríbete a nuestro blog para mantenerte al día con las últimas novedades!