Alta disponibilidad desde la cuna con FIS


En el 2023 empezamos a explorar el AWS Fault Injection Service (AWS FIS) para probar la resiliencia de nuestra arquitectura nueva de microservicios con ECS más Fargate la cual entró a complementar una arquitectura compuesta de Kubernetes sobre instancias EC2, esta era probada mediante un simple esquema de ChaosMonkey donde se apagaban instancias aleatorias en el cluster.
Antes de continuar explicamos brevemente de qué se trata FIS para entender mejor el proceso.
AWS Fault Injection Service
El servicio FIS (Fault Injection Service) es un componente de AWS que permite simular fallas de nuestra infraestructura, estas fallas se diseñan previamente y luego son ejecutadas, una falla previamente diseñada se conoce como "Experiment Template" y cuando este template se ejecuta se conoce como "Experiment".
Un "Experiment Template" se compone de "Actions" los cuales son fallos individuales que pueden afectar a ciertos targets, para nuestro caso de hoy, nuestro "Experiment Template" consiste en 2 "Actions" definidos de esta forma:
- ECS-Stop-Task: detiene los tasks del servicio de nuestro microservicio de prueba.
- Network-Stop_Traffic: bloquea el tráfico dentro de la subnet donde se encuentra nuestro microservicio (daremos más detalles en breve) de prueba por 10 minutos.
Combinando acciones, targets y experiment templates se pueden simular una gran cantidad de situaciones que van desde interrupciones de servicios específicos hasta caídas completas de Availability Zones. En nuestro caso, las dos acciones anteriores son suficientes para simular la caída de un Availability Zone para un task de ECS.
Nuestro objetivo será desplegar un microservicio de prueba, ejecutar nuestro template y anotar los resultados a medida que hagamos cambios para mejorar su resiliencia. De paso conocemos mejor a los sistemas de los que dependemos (API Gateway, VPC Links, CloudMap, ECR).
La víctima
El microservicio que desplegaremos es un task de la imagen hello-world-json el cual responde el siguiente objeto cada vez que es invocado `{ "message":"Hello World" }`. A esta imagen solo le agregamos el paquete `curl` para los healthchecks mediante una línea extra al Dockerfile, la imagen resultante la subimos al ECR de la cuenta.
El ring
Nuestro servicio se desplegará en un cluster ECS con Fargate, tendrá un endpoint público expuesto mediante AWS API Gateway, que se conectará al backend mediante una combinación a través de un VPC-Link, que le permitirá llegar a la red interna donde se despliega el servicio, y este servicio tendrá configurado el Service Discovery con un namespace dedicado de Cloudmap.
Método de prueba
Para probar que tanto afectan los escenarios de fallo de FIS al microservicio, corremos un script que envía peticiones simulando ser un cliente durante el tiempo que dure la prueba, este script nos devuelve los siguientes números:
- Porcentaje de uptime percibido por el cliente durante el proceso.
- Tiempo de respuesta promedio del servicio en milisegundos.
Al script lo llamamos uptime.sh y tiene el siguiente contenido:
#!/bin/bash
url="$1" # URL a probar
duration_in_seconds="$2" # Duración de la prueba en segundos
total_requests=0
total_time=0
success_count=0
failure_count=0
if [ -z "$url" ] || [ -z "$duration_in_seconds" ]; then
echo "Usage: $0 <url> <duration_in_seconds>"
exit 1
fi
for ((i=0; i<$duration_in_seconds; i++)); do
start=$(date +%s.%N)
response=$(curl -s --connect-timeout 1 -o /dev/null -w "%{http_code}" "$url")
end=$(date +%s.%N)
elapsed=$(echo "scale=3; $end - $start" | bc)
if [ $response -eq 200 ]; then
success_count=$((success_count + 1))
total_requests=$((total_requests + 1))
total_time=$(echo "$total_time + $elapsed" | bc)
else
failure_count=$((failure_count + 1))
total_requests=$((total_requests + 1))
fi
sleep 1
done
avg_response_time=$(echo "scale=3; $total_time / $success_count" | bc)
uptime_percentage=$(echo "scale=2; ($success_count / $total_requests) * 100" | bc)
echo "Average Response Time: $avg_response_time seconds"
echo "Uptime Percentage: $uptime_percentage%"El paso a paso seguido para las pruebas es el siguiente:
- Configurar el servicio de acuerdo al nivel de resiliencia.
- Correr el script de uptime por 10 minutos (600s).
- Inmediatamente ejecutar el experimento de FIS que dura 5 minutos.
- Esperar a que termine el script y anotar el resultado.
Progresión
Para nuestras pruebas realizamos los siguientes experimentos:
1. Conexión directa a IP a través de VPN sin FIS

En esta primera prueba ejecutamos el script apuntando directamente a la IP privada del microservicio a la cual se llega a través de una conexón VPN, y sin ejecutar el experimento, con esto tendremos el baseline de un resultado ideal.
- Average Response Time: .570 seconds
- Uptime Percentage: 100.00%
2. Conexión a través de API Gateway sin FIS

En esta prueba nuestro script se conecta al microservicio a través de un endpoint público de API Gateway sin ejecutar el experimento, con esto tenemos el baseline de la percepción de un cliente que se conecta a través de internet.
- Average Response Time: .890 seconds
- Uptime Percentage: 100.00%
Aquí vemos que el servicio de API Gateway agrega unos 300ms de latencia.
3. Conexión a través de API Gateway en subnet diferente con disrupciones y una sola replica
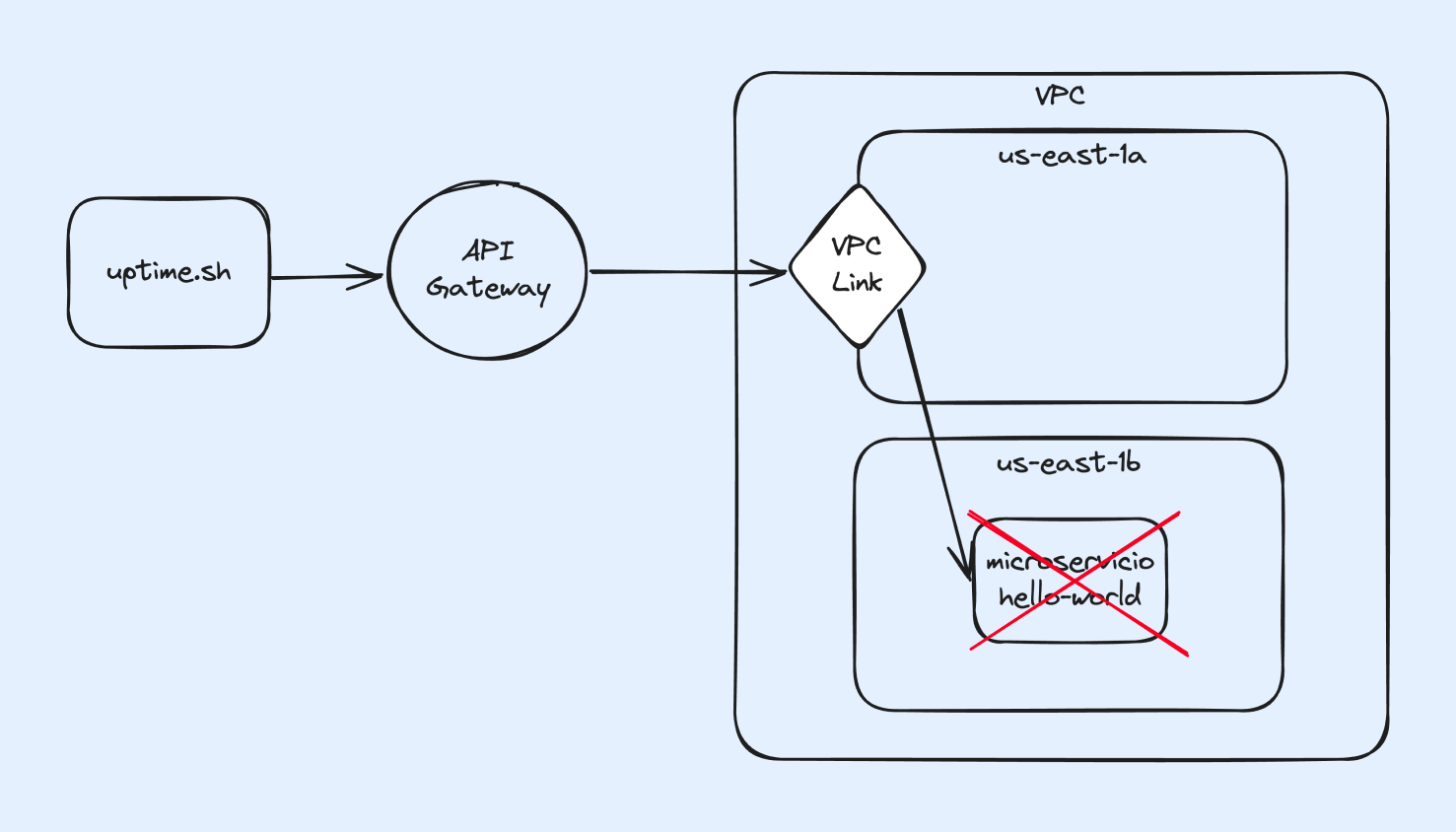
Para este caso, el VPC-Link de nuestro API Gateway se encuentra en una subnet distinta a la de nuestro task, esta sería nuestro worst case scenario.
- Average Response Time: .945 seconds
- Uptime Percentage: 24.00%
Aquí vemos que al correr el experimento, el uptime se ve muy afectado ya que el task solo termina de desplegarse cuando termina la disrupción causada por FIS, y luego se tarda un momento en restablecer la conexión entre las subredes diferentes.
4. Conexión a través de API Gateway en misma subnet con disrupciones y una sola replica
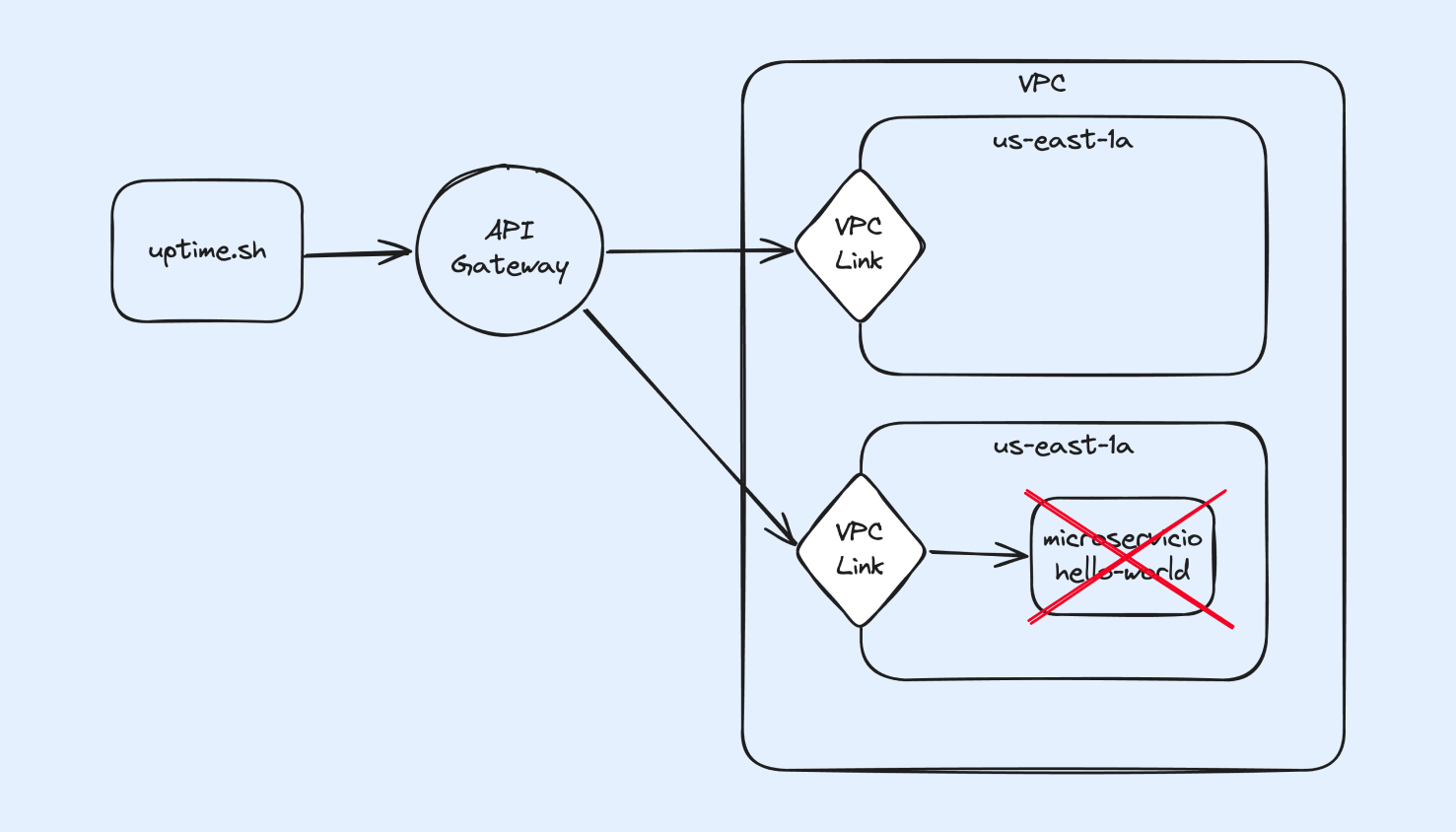
Aquí ubicamos el VPC-Link en las dos subredes.
- Average Response Time: .892 seconds
- Uptime Percentage: 74.00%
En este caso notamos que el uptime mejora, al no haber cambios en el tiempo que tarda en desplegarse de vuelta el servicio, asumimos que el hecho de estar en la misma red del VPC-Link ayuda bastante.
5. Conexión a través de API Gateway con múltiples réplicas y disrupciones
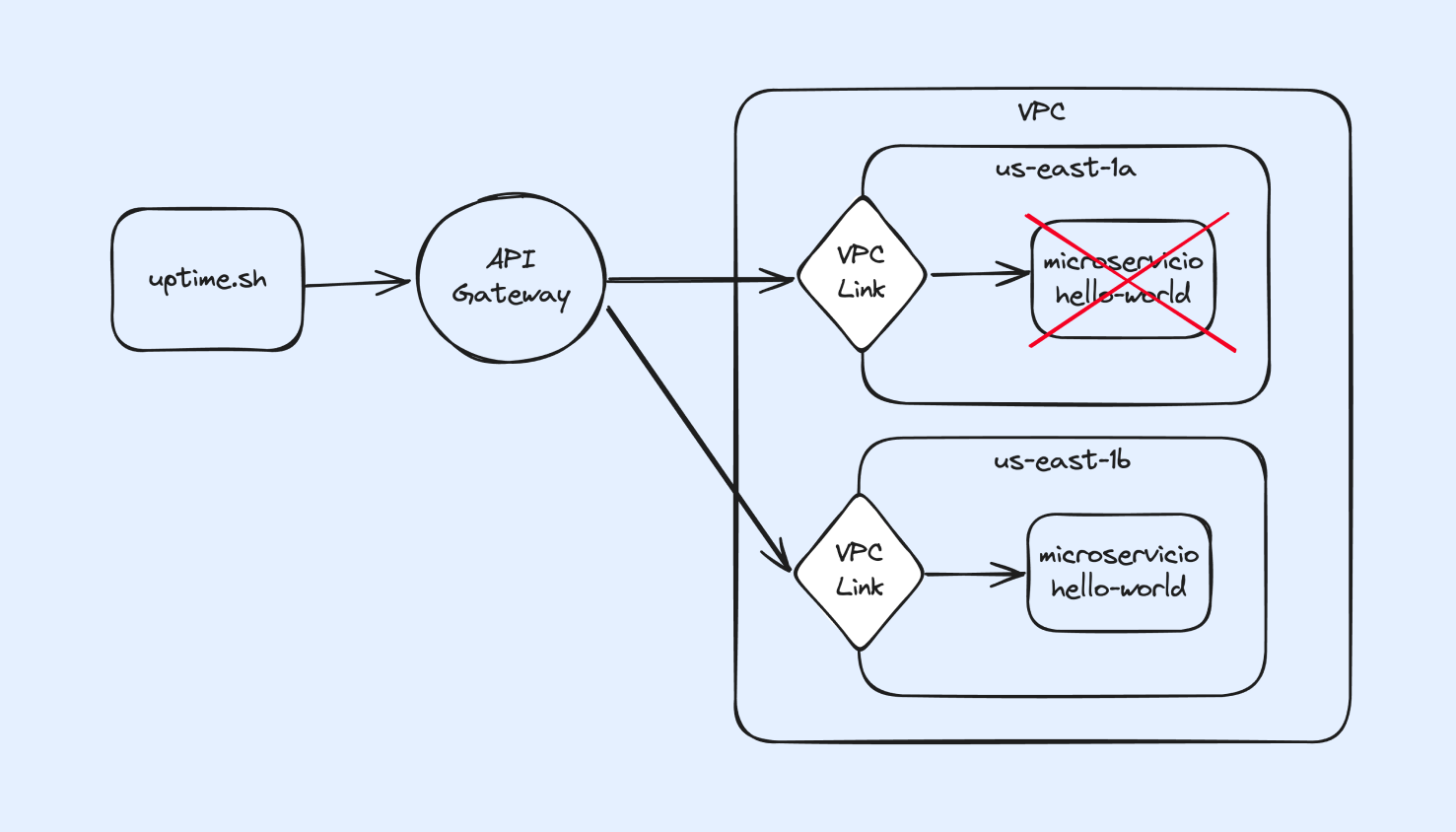
Aquí nuestro VPC-Link y el servicio se crean en las dos subredes.
- Average Response Time: .884 seconds
- Uptime Percentage: 86.00%
Para esta prueba esperabamos ver un 100% de uptime, ya que nuestro experimento solo detiene una de las tasks, pero ya que el API Gateway ubica al microservicio a través de CloudMap, el cual al seguir siendo un servicio DNS, puede seguir reportando la IP del task detenido, incluso con el flag "Enable Amazon ECS task health propagation" activado, el cual tiene como objetivo informar inmediatamente a Route 53 de caídas de servicios.
Conclusión
Si bien nuestro experimento no fue muy complejo (comparado a algunos escenarios que pueden llegar a tener decenas de actions y durar hasta 12 horas) de todos modos nos dejó observar, documentar y ajustar el comportamiento de nuestro microservicio en condiciones que ocurren en la vida real y en los peores momentos. Esto nos parece extremadamente valioso ya que por ejemplo, el insight del uptime inesperado del caso 5, nos puede ahorrar un dolor de cabeza y muelas en el caso de haber llevado un microservicio a producción con la confianza de que varias réplicas y un API Gateway nos garantizaban un 100% de uptime.
Como siempre los invitamos a suscribirse y dejar sus comentarios. Hasta la próxima.