DevOps en sistemas legacy

En fintech.works estamos acostumbrados a lidiar con sistemas relativamente modernos donde aplicar un circuito de CI/CD robusto es relativamente sencillo, esto es posible gracias a que por lo general tenemos estas facilidades:
- Ciclos de desarrollo con tiempos y componentes bien definidos.
- Posibilidad de tests automatizados.
- Frameworks modernos.
- Modularización gracias a microservicios y APIs dedicadas.
- Documentación accesible.
- Utilizan "cloud-computing".
- Facilidad a la hora de probar mejoras.
Estas facilidades nos facilitan la vida inmensamente pero no nos libran de todo mal, en más de una ocasión nos encontramos con arquitecturas que cumplían con todos nuestros deseos pero aún así nos complicaron la vida con sus particularidades a la hora de implementar el ciclo de vida CICD.
Lo anterior es normal para nosotros y estamos acostumbrados a cumplir, e incluso mejorar, lo que inicialmente nos proponíamos, por otro lado, a veces nos topamos con proyectos menos glamorosos, los "Sistemas Legacy", que si bien suelen tener sus años, aún se encargan de tareas críticas en industrias como bancos, seguros, medicina y manufactura. Estos sistemas aún tienen muchos años de vida y suelen estar rodeados de sistemas más modernos con equipos, herramientas y procesos DevOps muy sofisticados y que se deben hacer cargo de tratar de modernizarlo o en su defecto mantenerlo vivo como sea necesario. Para estos casos la pregunta no es "si" DevOps puede encargarse de estos sistemas sino "como".
Los problemas de sistemas Legacy
Podemos tomar la lista de facilidades de la sección anterior y ponerla de cabeza para saber cuales son los problemas de los sistemas legacy:
- Ciclos de desarrollo largos que hacen imposibles las iteraciones y feedback rápidos.
- Pruebas manuales y burocráticas.
- Frameworks antiguos (si tenemos suerte) o directamente código sin framework ni convenciones.
- Código altamente acoplado difícil de modularizar e independizar.
- Poco o nada de monitoreo y documentación.
- Corriendo en bare-metal y hardware especializado.
- Miedo extremo a romper el sistema lo que desalienta la experimentación o modernización.
Estos problemas tienen en común que son ideales para ser solucionados aplicando los principios DevOps, que son exactamente lo que se necesita para mantenerlos relevantes y confiables.
Historias de éxito: DevOps aplicado a Legacy
Hablando de problemas de sistemas Legacy, a continuación listamos los casos de éxito más famosos donde se logró integrar DevOps de forma exitosa, si bien todos los casos sufrían más de uno (o todos) los problemas de la lista anterior, elegimos centrarnos en uno solo por cada caso.
Firmwares de HP LaserJet - Burocracia
Utilizaremos el siguiente ejemplo para mostrar como la burocracia afecta a los sistemas legacy.
En el año 2006 HP empezó a enfocar sus esfuerzos en mejorar la productividad de sus desarrolladores en el área dedicada a los firmwares para la familia de productos LaserJet, finalmente lograron aumentar la productividad entre 100 a 200%. El problema más importante era el nivel de burocracia que existía para llevar un cambio hasta producción, en resumen se enfrentaban a:
- Se tardaba una semana para saber si un cambio fue integrado correctamente y hasta 6 semanas en caso de ser necesaria una prueba manual.
- Las pruebas manuales implicaban probar directamente en una impresora real.
- Los errores en las pruebas se manifestaban semanas después de ser introducidos.
Los pasos más importantes que dieron para mejorar la situación fueron:
- Usar el modelo trunk-based: antes cada modelo de impresora tenía su propia rama de desarrollo, con condicionales en tiempo de compilación para diferenciarlos, esto multiplicaba la cantidad de tests que afectaba el código común entre todas, al pasarse al model trunk-based, la diferenciación entre modelos se hacía en tiempo de ejecución, siendo este el cambio más significativo ya que se pudieron normalizar los tests.
- Pruebas automatizadas: la dependencia de pruebas manuales en impresoras reales dificultaba la mejora de los tiempos en los tests, para esto se decidió enfocarse en pruebas mediante simuladores y emuladores. Al cambiar el enfoque se redujo el tiempo de pruebas a alrededor de 24 horas.
Los cambios anteriores en el modelo burocrático muestran la importancia de tener feedback rápido en los ciclos de desarrollo.
ING Bank – Problemas con la rigidez organizacional
Utilizaremos este ejemplo para mostrar cómo la rigidez organizacional puede dificultar la evolución de sistemas legacy.
Antes de adoptar DevOps, ING operaba con estructuras de equipos jerárquicas y muy compartimentadas. Había departamentos separados para desarrollo, testing, operaciones y seguridad, lo que generaba cuellos de botella cada vez que un cambio debía avanzar por estas capas. Los equipos no compartían métricas, responsabilidades ni objetivos, lo cual hacía que las prioridades se desalinearan fácilmente. Esto se traducía en semanas o incluso meses para entregar nuevas funcionalidades o resolver incidentes.
ING decidió reorganizar sus equipos siguiendo el modelo Spotify, dividiendo a sus equipos en squads multidisciplinarios con autonomía para desarrollar, probar y desplegar. Este cambio estructural fue acompañado por:
- Cultura de “You build it, you run it”, donde cada equipo era dueño de su servicio.
- Automatización de pruebas y despliegues, lo cual redujo drásticamente el tiempo de entrega.
- Migración a pipelines CI/CD, que permitió lanzar cambios de forma segura varias veces al día.
Gracias a estos cambios, los tiempos de entrega pasaron de semanas a horas. El caso muestra cómo una estructura organizacional poco flexible puede ser más limitante que el propio sistema legacy, y que atacar este problema puede generar mejoras inmediatas.
Target – Acoplamiento entre sistemas
Este caso ilustra cómo el alto nivel de acoplamiento entre componentes puede dificultar la modernización.
Target, uno de los principales retailers en EE.UU., enfrentaba una gran dependencia entre sus sistemas legacy. Cambiar una funcionalidad del sistema de facturación podía impactar al sistema de inventario, y viceversa. Esto limitaba la velocidad de desarrollo y aumentaba el riesgo de errores en producción.
La solución fue crear una arquitectura de microservicios alrededor de los sistemas existentes, lo cual permitió “desacoplar” funcionalidades sin reemplazar todo el sistema de golpe. En particular:
- Se comenzaron a encapsular funcionalidades con APIs que actuaban como intermediarios entre sistemas modernos y legacy.
- Se implementaron colas de eventos (Kafka, RabbitMQ) para romper las dependencias sincrónicas entre componentes.
- Se introdujo infraestructura como código para permitir ambientes consistentes de testing y producción.
El resultado fue una mayor independencia entre equipos, mejor resiliencia del sistema ante fallos, y una base sólida para seguir modernizando sin tocar todo de una vez. El caso muestra cómo un sistema acoplado no solo es más difícil de mantener, sino también de hacer evolucionar.
Capital One – Problemas con la infraestructura tradicional
Este caso expone cómo una infraestructura tradicional puede frenar la adopción de prácticas modernas como DevOps.
Capital One, uno de los bancos más grandes de EE.UU., quería acelerar su ciclo de desarrollo. Sin embargo, estaba limitado por su infraestructura on-premise, donde provisionar un servidor nuevo podía tardar semanas y escalar una aplicación implicaba procesos manuales e inseguros.
La clave fue migrar progresivamente a AWS. Esto no fue una simple “mudanza al cloud”, sino parte de una estrategia más amplia que incluía:
• Automatización total de infraestructura con Terraform y CloudFormation.
• Contenerización de aplicaciones legacy usando Docker, facilitando su portabilidad.
• Integración de pipelines CI/CD con servicios nativos de AWS (CodePipeline, CodeDeploy).
Este enfoque redujo drásticamente los tiempos de aprovisionamiento y permitió a los equipos desplegar múltiples veces por día. Aquí se ve claramente cómo una infraestructura inflexible puede ser uno de los principales cuellos de botella en un sistema legacy, y cómo el paso al cloud puede destrabar mejoras más allá del plano técnico.
Maersk – Falta de visibilidad y monitoreo
Este ejemplo muestra cómo la falta de visibilidad sobre el comportamiento de los sistemas afecta tanto la estabilidad como la capacidad de mejora continua.
Maersk, la empresa de logística y transporte marítimo más grande del mundo, sufría frecuentes interrupciones de servicio en sus sistemas legacy. Uno de los mayores problemas era que los incidentes eran detectados tarde, a veces gracias a una llamada de un cliente, y la trazabilidad de errores era limitada.
Para resolver esto, Maersk adoptó un enfoque de observabilidad completo:
• Instrumentación de código legacy con métricas y logs estructurados.
• Uso de herramientas modernas como ELK stack y Prometheus/Grafana.
• Implementación de tracing distribuido para identificar cuellos de botella entre servicios.
Este cambio permitió detectar errores en minutos, en lugar de horas o días, y redujo significativamente el MTTR (tiempo medio de recuperación). El caso ilustra cómo la visibilidad y monitoreo no son un lujo moderno, sino un requisito básico cuando se trabaja con sistemas complejos y antiguos.
UK Government Digital Service (GDS) – Dependencia de procesos manuales
Este caso se centra en cómo los procesos manuales ralentizan y fragilizan la operación de sistemas legacy.
El GDS enfrentaba el reto de mantener sistemas como el de impuestos y salud pública, muchos de los cuales dependían de procesos manuales para tareas tan básicas como despliegues o respaldo de datos. Esto generaba tiempos de espera largos, errores humanos frecuentes y un alto costo operativo.
La estrategia que siguieron fue construir una “capa de modernización” alrededor del legacy:
• Crearon APIs para encapsular funcionalidades sin tener que reescribirlas.
• Automatizaron los procesos clave como los despliegues y las validaciones de seguridad.
• Migraron servicios secundarios (como autenticación o notificaciones) a soluciones modernas en la nube.
Gracias a esto, lograron entregar servicios digitales nuevos sin reemplazar por completo los sistemas existentes. El caso muestra cómo atacar la dependencia de lo manual con automatización progresiva puede liberar tiempo, reducir errores y crear una base para seguir modernizando.
Lecciones y oportunidades
Armamos el siguiente gráfico que resume qué areas pueden ser mejoradas aplicando los cambios de los casos que vimos:
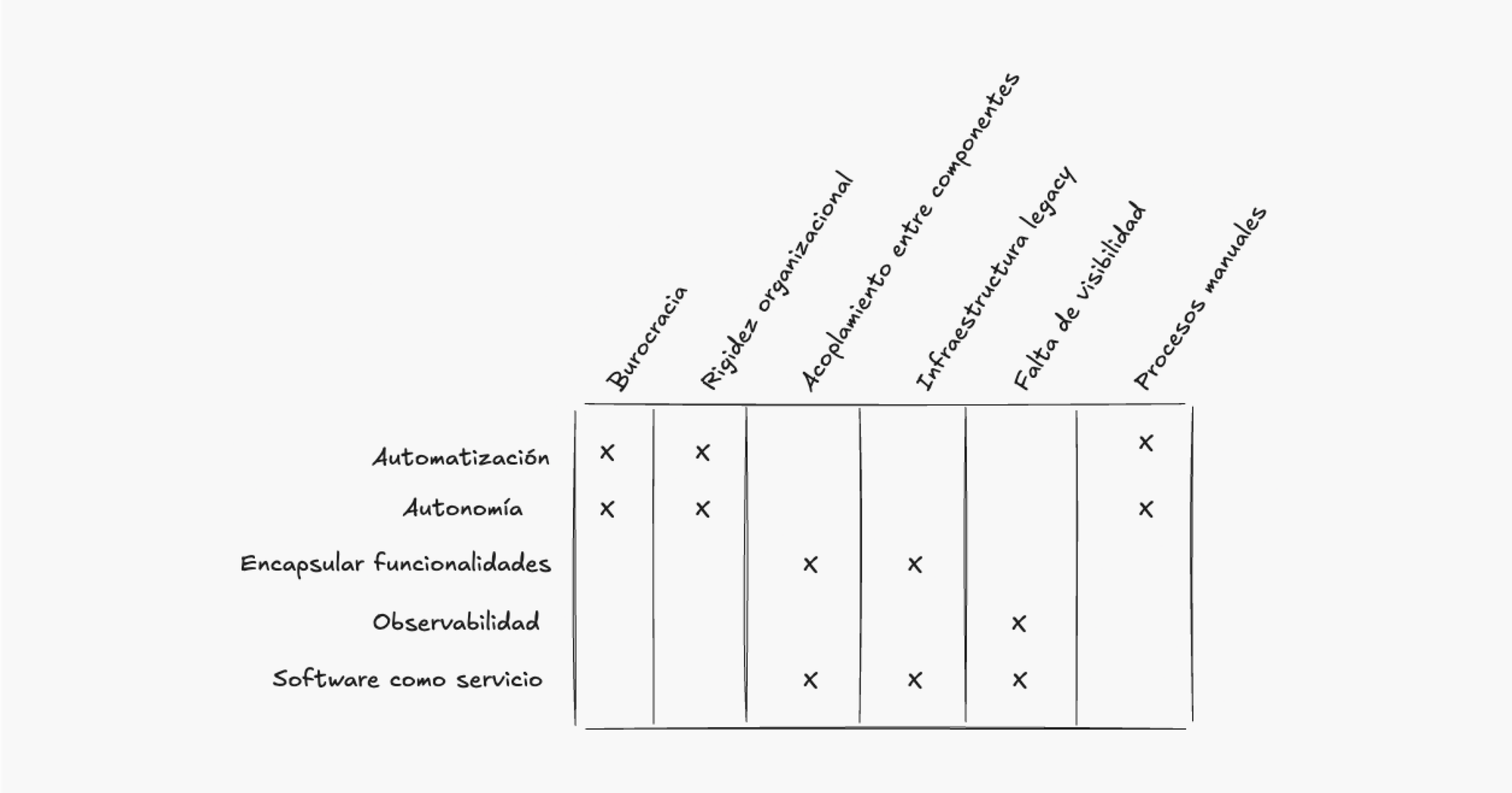
Estos cambios vienen acompañados de lecciones que podemos aplicar en otros sistemas legacy:
- No esperar por el cambio perfecto: La modernización incremental funciona mejor y viene con menos riesgos.
- Enfocarse primero en automatización: Esas pequeñas mejoras en testing o despliegue son la base de las mejoras grandes.
- Usar DevOps para guiar la evolución de la arquitectura: Construyendo pipelines alrededor de componentes y evolucionando el sistema hacia la modularidad.
- Empoderar equipos: dando acceso a herramientas, autonomía y feedback que necesitan para experimentar y mejorar el código legacy.
En nuestra experiencia, no hay un orden predefinido para aplicar estos cambios. En algunos proyectos, el código base está tan deteriorado que una reescritura parcial o total es inevitable. En otros, el problema principal no es técnico, sino de comunicación: equipos que no se hablan, procesos llenos de pasos manuales, o un miedo generalizado al cambio. Y hay casos donde simplemente empezar a hacer pequeños ajustes (como agregar pruebas unitarias o automatizar una sola tarea repetitiva) crea un proceso positivo que se va acelerando con el tiempo.
Por eso, antes de tomar cualquier decisión técnica, lo más importante es sentarse a hablar con las personas que conocen y mantienen ese sistema legacy. Ellos son quienes viven el día a día, conocen los verdaderos cuellos de botella, y pueden señalar dónde está el dolor real. Escuchar sus experiencias y frustraciones es clave para priorizar los primeros pasos de la transformación y para asegurarse de que los cambios que se propongan realmente tengan impacto.