El rol del feedback en DevOps


Estamos por alcanzar un año entero de publicaciones mensuales en este blog, un año donde hablamos sobre temas específicos del área DevOps en los cuales tratamos de mostrar nuestra forma de encarar los desafíos que nos surgen.
Para esta publicación trataremos algo más general sin la intención de enseñar sobre un tema en particular. Esta vez hablaremos sobre una de las partes más importantes de esta área que son los "feedback loops".
Concepto
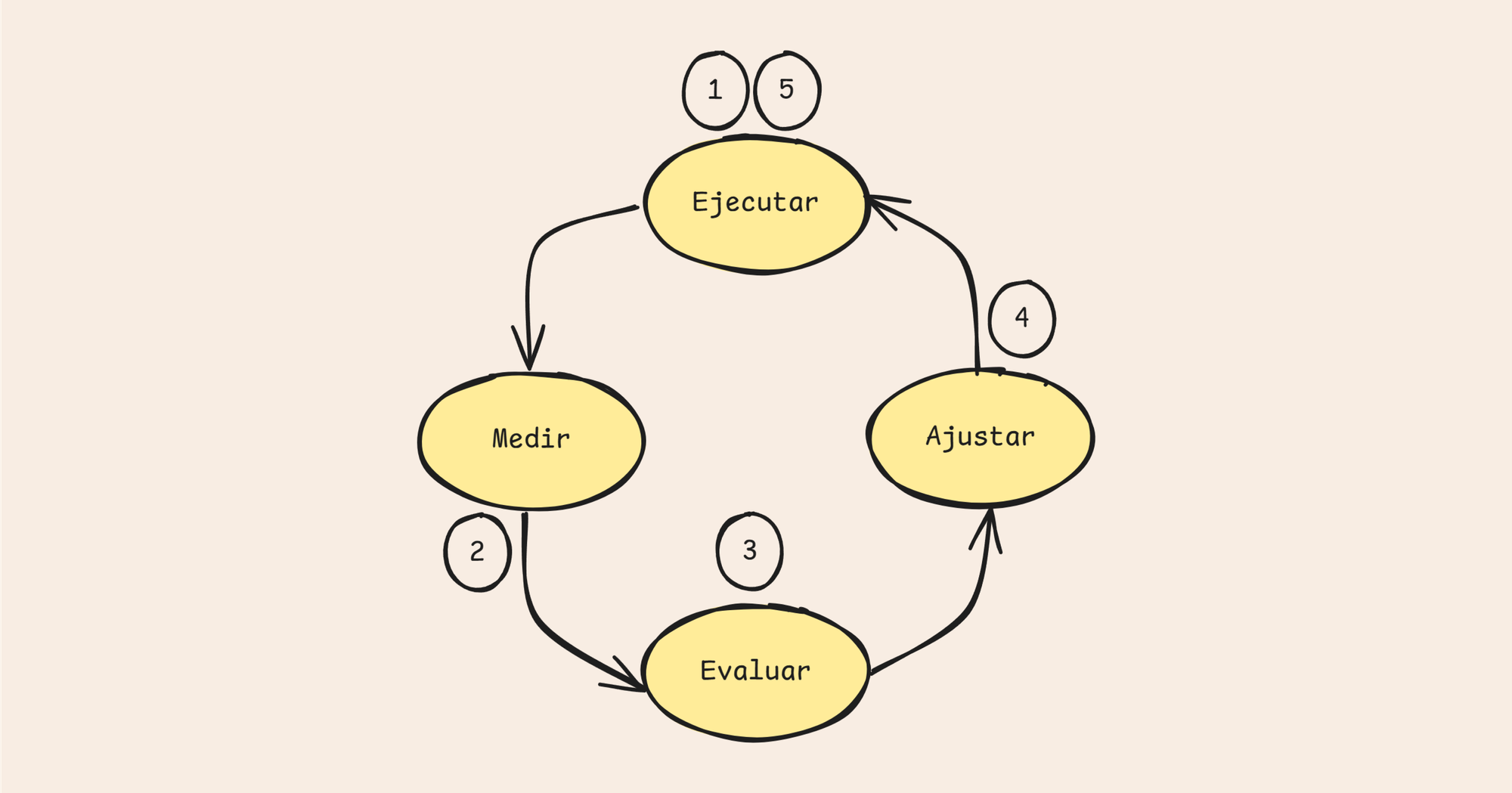
La siguiente imagen muestra un feedback loop típico, donde:
- Ejecutamos una acción.
- Alguien nos retorna el resultado de la acción.
- De nuestro lado evaluamos el resultado.
- Ajustamos en base a la evaluación.
- Volvemos a ejecutar la acción.
Este loop aparece en nuestro día a día casi sin darnos cuenta, por ejemplo sigamos el proceso de hacer un trámite para obtener un documento oficial:
- Presentamos una serie de documentos requeridos.
- Un funcionario nos comunica que necesitamos una copia de uno de los documentos y venir a una hora diferente.
- Pensamos si podríamos hacer la copia en un lugar cercano y hacerlo todo ahora o mejor dejarlo para otro día, tomamos una decisión para ambos casos.
- Conseguimos la copia y agendamos un horario para el trámite.
- Nos acercamos en el horario correcto con la copia del documento.
Este ejemplo muestra el loop ideal donde alcanzamos el objetivo en una sola iteración, pero no significa que no se pueda complicar con problemas como estos:
- Nos comunican que nos faltan documentos luego de haber empezado el trámite.
- La lista de documentos requeridos cambia constantemente.
- La atención es lenta.
- El funcionario nos da información incompleta por lo que tenemos que volver en otra fecha con más documentos.
- La oficina no está abierta a la hora que nos conviene.
Estos problemas pueden ocurrir en cualquiera de los 5 pasos y pueden ser pequeñas inconveniencias o volverse problemas complejos que nos desalientan a seguir con el proceso y reducen la confianza hacia el mismo.
Un buen feedback loop
Ya vimos el esquema y los problemas básicos, ahora hablaremos sobre las cualidades que debería tener un buen feedback loop.
- Requisitos claros y sencillos: el proceso inicial debería tener una lista de requisitos cuyas especificaciones estén bien documentadas y accesibles por cualquiera que lo necesite.
- Respuesta correcta y oportuna: antes de iniciar el proceso se deberían chequear los requisitos y luego de iniciar el proceso deberíamos tener una respuesta sobre el estado del proceso, si no se pudo completar se deberían listar los motivos específicos.
- Facilidad de corrección: en caso de problemas deberíamos tener una lista de motivos por los cuales está ocurriendo una falla y si es posible los pasos para solucionarlos en caso de ser problemas conocidos.
- Agilidad: todo lo anterior debería ocurrir lo más rápido posible para evitar tiempos muertos en el proceso.
- Consistencia: en caso de tener varios feedback loops para distintos procesos que son utilizados por el mismo grupo de personas, estos deberían ser parecidos y consistentes entre sí.
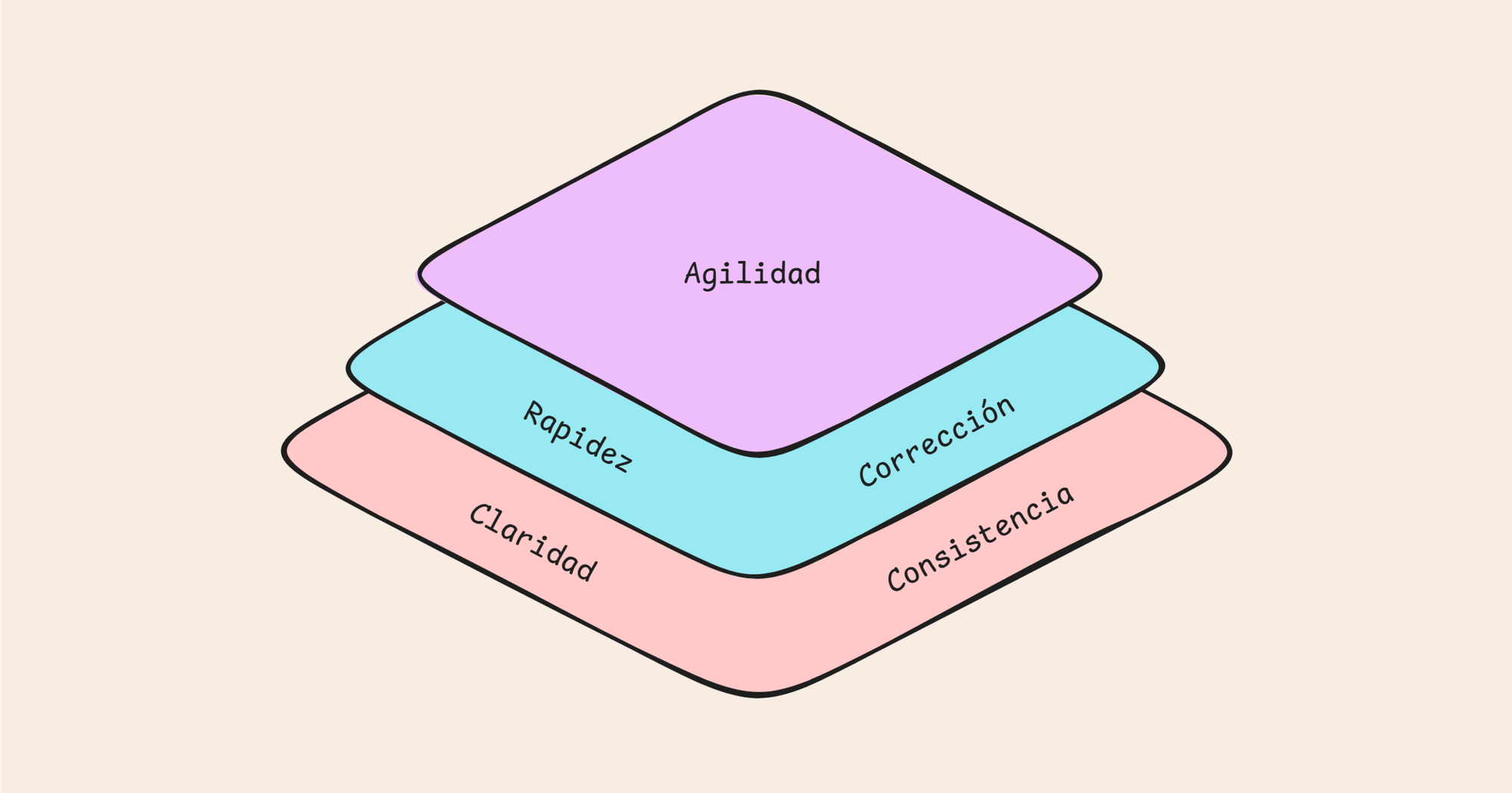
Como vemos en el siguiente gráfico estas cualidades también están relacionadas entre sí:
Base (Fundamento del feedback loop)
- Claridad (Requisitos claros y sencillos) → Si no hay requisitos claros, todo el proceso será defectuoso.
- Consistencia (Uniformidad entre loops) → Mantiene un estándar en todos los procesos.
Nivel intermedio (Ejecución del feedback loop)
- Rapidez (Respuesta correcta y oportuna) → Con requisitos claros y consistencia, el sistema puede responder rápido.
- Corrección (Facilidad de corrección) → Si hay claridad y rapidez, los errores pueden identificarse fácilmente.
Cima de la pirámide (Optimización del feedback loop)
- Agilidad (Evitar tiempos muertos) → Es el resultado de todo lo anterior funcionando bien. Si la base es sólida, el proceso puede ser ágil.
Llevando feedback loops a DevOps
Las cualidades anteriores pueden ser aplicadas a los ciclos de cualquier área de la informática, desde el QA, pasando por el desarrollo hasta llegar a la propia infraestructura. En el área de DevOps podemos aplicar estas cualidades al componente más importante de esta área que es el pipeline CI/CD.
Para este ejemplo veamos un pipeline CI/CD genérico que tiene como objetivo tomar un cambio hecho por un developer y pasarlo a producción. Este proceso sigue los siguientes pasos:
- Developer hace un PR a una rama.
- El pipeline toma el cambio y le aplica una serie de pruebas.
- El pipeline retorna el resultado de las pruebas.
- El developer ajusta el código para cumplir con los requisitos.
- El pipeline vuelve a probar y lo mueve a un ambiente de pruebas.
- El pipeline realiza pruebas sobre el ambiente de pruebas y reporta los resultados.
- El developer ajusta el código.
- Cuando las pruebas son satisfactorias, se pasa el código al ambiente de QA.
- Aquí es probado por un equipo de QA y los resultados son comunicados al developer, el cual reinicia el proceso para realizar ajustes.
Gracias a nuestra experiencia de varios años manteniendo pipelines de este tipo podemos tomar cada paso y explicar cómo lograr las buenas cualidades en cada uno.
Pasos 1 al 4 - Pull requests a ramas de desarrollo
A la hora de integrar código lo importante es el review que hace el desarrollador senior, el pipeline toma un rol de soporte haciendo chequeos de:
- Linting: búsqueda rápida de errores de sintaxis en base a reglas predefinidas, ideal para mantener consistencia entre distintos tipos de ambientes de desarrollo o equipos.
- Formateo de código: chequeo de formato para mejorar la legibilidad.
- Políticas de desarrollo: aquí verificamos que se siga el esquema de nombres de ramas, commits, versiones, etc.
- Seguridad básica: chequeo superficial en busca de secretos, keys, contraseñas, tokens, etc.
- Compilación sin tests: probamos la compilación del código sin tests.
Viendo estos 5 procesos vemos que cada uno contribuye a las buenas cualidades, cada uno de estos chequeos produce un resultado claro del tipo "Ok" o "Fail", se ejecutan rápidamente, y contribuyen a agilizar las siguientes etapas. Estos resultados se reportan en comentarios directamente en los pull-requests quedando accesibles solo para todos los involucrados en el mismo, al mismo tiempo ayudan a los desarrolladores senior a enfocarse en el código útil.
Pasos 5 al 7 - Pruebas en desarrollo
Con la bendición del desarrollador senior y tests ligeros aprobados se pasa a la siguiente etapa donde se toma el código y se despliega en un ambiente, en nuestro caso un ambiente de desarrollo donde es puesto a prueba conectado a todos sus sistemas complementarios.
En este ambiente se ejecutan las pruebas más profundas:
- Preparación de ambiente de pruebas: creamos una base de datos nueva y aplicamos las últimas migraciones.
- Compilación con tests: aquí compilamos el código ejecutando los tests unitarios apuntando al ambiente de prueba.
- Creación de paquetes: se prepara el código para ser desplegado en una imagen Docker, esta imagen es ubicada en el registry del ambiente.
- Despliegue: la nueva versión es desplegada en el ambiente de prueba, este ambiente es monitoreado por una herramienta externa que reporta el downtime en un canal interno.
- Reporte: el resultado del despliegue es publicado en un canal de comunicación interno.
De vuelta destilamos las buenas cualidades de estos procesos:
Esta etapa tiene objetivos claros y precisos que son pasar tests y ser desplegado correctamente, produce respuestas claras avisando en los canales internos cuando falla la compilación o no se puede desplegar (mediante la métrica de downtime).
También facilita la corrección ya que sabemos que los problemas están localizados en los tests, base de datos o ambiente de pruebas e incluimos un mensaje de resumen del error y un link al job o paso que falló junto con la información relevante como número de pull request y autor. Otro punto positivo es que detectamos y documentamos las modificaciones necesarias al ambiente que luego serán necesarias para QA y producción.
Logramos agilidad al ser un proceso totalmente automatizado que se activa al hacerse el merge.
Pasos 7 al 9 - Pase a QA y producción
Para el pase al ambiente a QA el pipeline vuelve a tomar un rol de soporte, a la hora de hacer un merge a la rama de este ambiente se ejecutan las mismas pruebas que en los pasos 1 al 4, y queda a cargo del responsable del ambiente aceptar el pull-request.
Luego de aprobarse el PR, se generan las imágenes correspondientes al ambiente y se procede al despliegue, igual que en los pasos 5 al 7, el ambiente de QA es monitoreado continuamente y cualquier error en el proceso de despliegue es reportado inmediatamente. Esta etapa solo es diferente del pase a desarrollo en el hecho de que las bases de datos no son restablecidas en cada despliegue.
Para el pase al ambiente de producción se sigue el mismo esquema que en QA, manteniendo la consistencia.
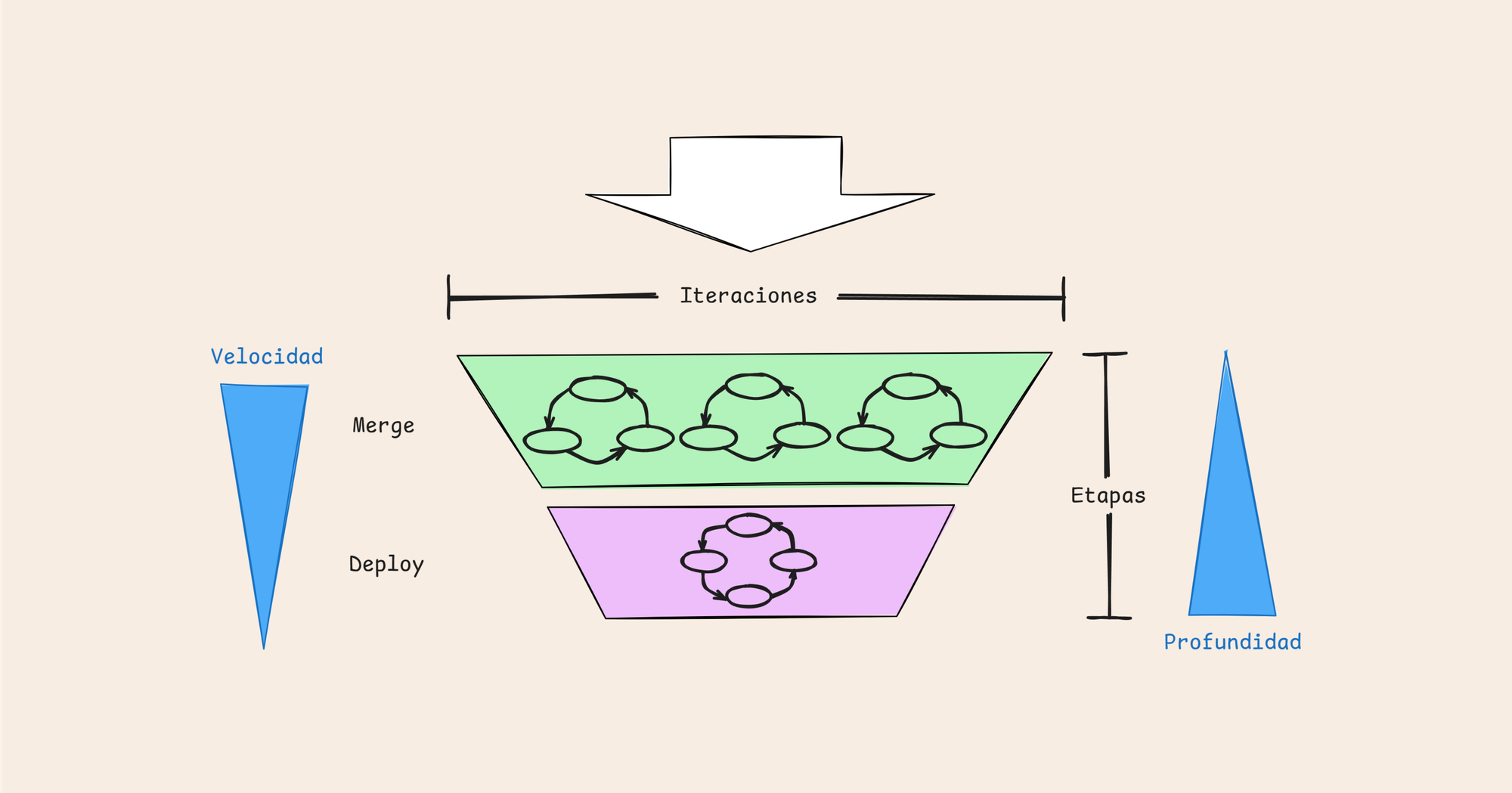
En el siguiente gráfico vemos el comportamiento típico de los dos tipos de pipelines en funcionamiento, donde aquellas que tienen como objetivo validar integraciones al repositorio son más rápidas y superficiales con feedback rápido. Mientras que las dedicadas a validar despliegues son más profundas y por ende más lentas.
Consistencia
Según nuestra experiencia, la consistencia para el desarrollador es un punto extremadamente importante, nos referimos específicamente a que los pipelines de todos los proyectos que son mantenidos por un equipo particular de desarrolladores deben comportarse de la misma manera.
Lastimosamente esto no siempre es posible ya que algunos proyectos requieren tecnologías muy diferentes o tiempos apretados que obligan a tomar atajos o crear excepciones, las cuales si bien son inicialmente beneficiosas, a la larga terminan causando muchos problemas a la hora de hacer troubleshooting junto a dolores de cabezas debido a los problemas de requisitos extra, tiempos diferentes y expectativas incorrectas, sin olvidar el hecho de que algunos proyectos quedan suspendidos por un tiempo y esto dificulta aún más retomarlos.
Por lo anterior recomendamos que todos los pipelines sean iguales, pero si no es posible, mantener consistencia en estos puntos:
- Canales de comunicación: los pipelines deberían reportar sus resultados solo en los pull-requests, no debería ser necesario consultar otro canal o log para saber que un pipeline se ejecutó correctamente.
- Evitar pasos manuales: los pipelines no deberían requerir intervención manual en ningún momento salvo en casos de errores y pasos a ambientes sensibles.
- Separar tests ligeros y pesados: los chequeos de lint, políticas y parecidos deben hacerse en etapas separadas de los tests que prueben el código en funcionamiento.
- Alertas de despliegue globales: en caso de ocurrir problemas que afectan a un ambiente utilizado por más de un equipo de desarrollo, esto se debe notificar a todos, ya que hay una gran probabilidad de que los problemas no sean causados por el cambio actual y dependa de otros microservicios o artefactos, en estos casos la solución suele manifestarse más rápido.
Conclusión
Los feedback loops son la pieza más importante para el proceso DevOps, ya que permiten detectar problemas de manera temprana, facilitar correcciones y mejorar continuamente los procesos. Desde la integración de código hasta el despliegue en producción, cada etapa del pipeline CI/CD se beneficia de loops de retroalimentación bien diseñados.
Como hemos analizado, la claridad en los requisitos, la rapidez en las respuestas, la facilidad de corrección, la agilidad y la consistencia son cualidades esenciales de un buen feedback loop. Aplicarlas correctamente en nuestros procesos no solo optimiza el flujo de trabajo, sino que también fortalece la confianza en el sistema y mejora la experiencia de los desarrolladores.
Si bien lograr una implementación completamente homogénea en todos los proyectos puede ser un reto, mantener una estructura consistente y alineada con buenas prácticas permite minimizar fricciones y reducir el tiempo de resolución de problemas. Al final, un feedback loop eficiente no solo acelera el desarrollo, sino que también promueve una cultura de mejora continua dentro de los equipos DevOps.