Errores como contrato


En nuestro blog sobre pruebas de contrato contamos nuestra experiencia implementando contratos para microservicios y cómo estos sirven para facilitar el desarrollo y la documentación dentro de una organización. En aquella ocasión no llegamos a mirar en detalle un contrato real en sí, sino que simplemente dimos una explicación general del concepto del contrato y de cómo lo utilizamos, por lo que es recomendable que lo lean para entender mejor nuestro tema actual. Esta vez queremos ponerle foco a una parte muy importante dentro del mecanismo del contrato que es la que define los errores que nuestras APIs podrían responder.
Definiendo errores en contratos
Lo que suele pasar mucho a la hora de definir contratos es enfocarnos solamente en las respuestas correctas, ya que estas son las que requieren desarrollo del lado del cliente para poder llevar a cabo su objetivo, y estos clientes por lo general siempre esperan que la API responda correctamente.
Cuando se da la situación que las APIs solo responden información útil en casos de éxito y los clientes solo tiene en cuenta las respuestas correctas y cualquier error que ocurra es automáticamente descartado lo que ocurre es que se sobrecarga a los operadores tanto del cliente como de la API con rondas innecesarias de troubleshooting que pudieron evitarse si los errores retornaban un poco más de información.
Veamos un ejemplo básico de la vida real de una persona que va a un banco a retirar dinero, supongamos que la persona se acerca a la sucursal y presenta sus datos al cajero, quien verifica en su sistema estos datos y le dice a la persona: "Lo siento, usted no puede retirar dinero" sin más información. Al recibir esta respuesta, la persona que ya está habituada a este tipo de trato, hace una llamada al centro de atención al cliente y pasa por una ronda de espera de varios minutos para finalmente enterarse que la causa por la cual no estaba pudiendo retirar el dinero era que su número de teléfono debía ser actualizado, lo cual lo pudo haber hecho al momento en que intentó retirar, pero al haber recibido la respuesta recién ahora, deberá volver a repetir todo el circuito.
En este ejemplo, los personajes de la historia son: el banco, que representa a una API, la persona que representa al consumidor de la API y el centro de atención al cliente que toman el papel de los operadores o desarrolladores de ambas partes. Como podemos ver, si el banco (API) le comunicaba a la persona el problema con su número de teléfono (error de respuesta con información enriquecida), la persona (el cliente de la API) pudo haber reintentado con su número de teléfono actualizado y con esto agilizar la operación y evitar la llamada al centro de atención al cliente por un problema trivial.
Este ejemplo puede parecer muy básico pero es un fenómeno que ocurre mucho en APIs que siguen esta mala práctica de enfocarse en el happy path y no proveer información útil en casos de errores, con un error 400 o 500 suele ser suficiente para que los clientes se las arreglen por si solos. Pero como vimos en el ejemplo esto se puede mejorar, y mucho.
Problemas de errores mal definidos
Si bien el ejemplo mostró el problema fundamental con no tener respuestas de errores bien definidos, existen dos problemas mucho más específicos que surgen al no tener contratos con respuestas incompletas, estos son los contratos definidos por clientes y la imposibilidad de tomar decisiones de forma automatizada, veamos en detalle cada uno.
1. Obliga a los consumidores a inventar y mantener sus propios contratos
Cuando una API pública solo notifica que hubo un error sin dar detalles, cada consumidor de esta API se ve obligado a tomar acciones por su cuenta sin ningún estándar, si volvemos al ejemplo del banco, un cliente puede tomar la decisión de volver al banco al día siguiente, otro podría reintentar el retiro con otro cajero y otros podrían simplemente rendirse y pasar al banco de enfrente. Aquí cada cliente se verá obligado a tener su propio contrato definido en su lógica de negocio, por ejemplo, algunos podrían hacer reintentos N cantidad de veces y otros podrían directamente fallar internamente.
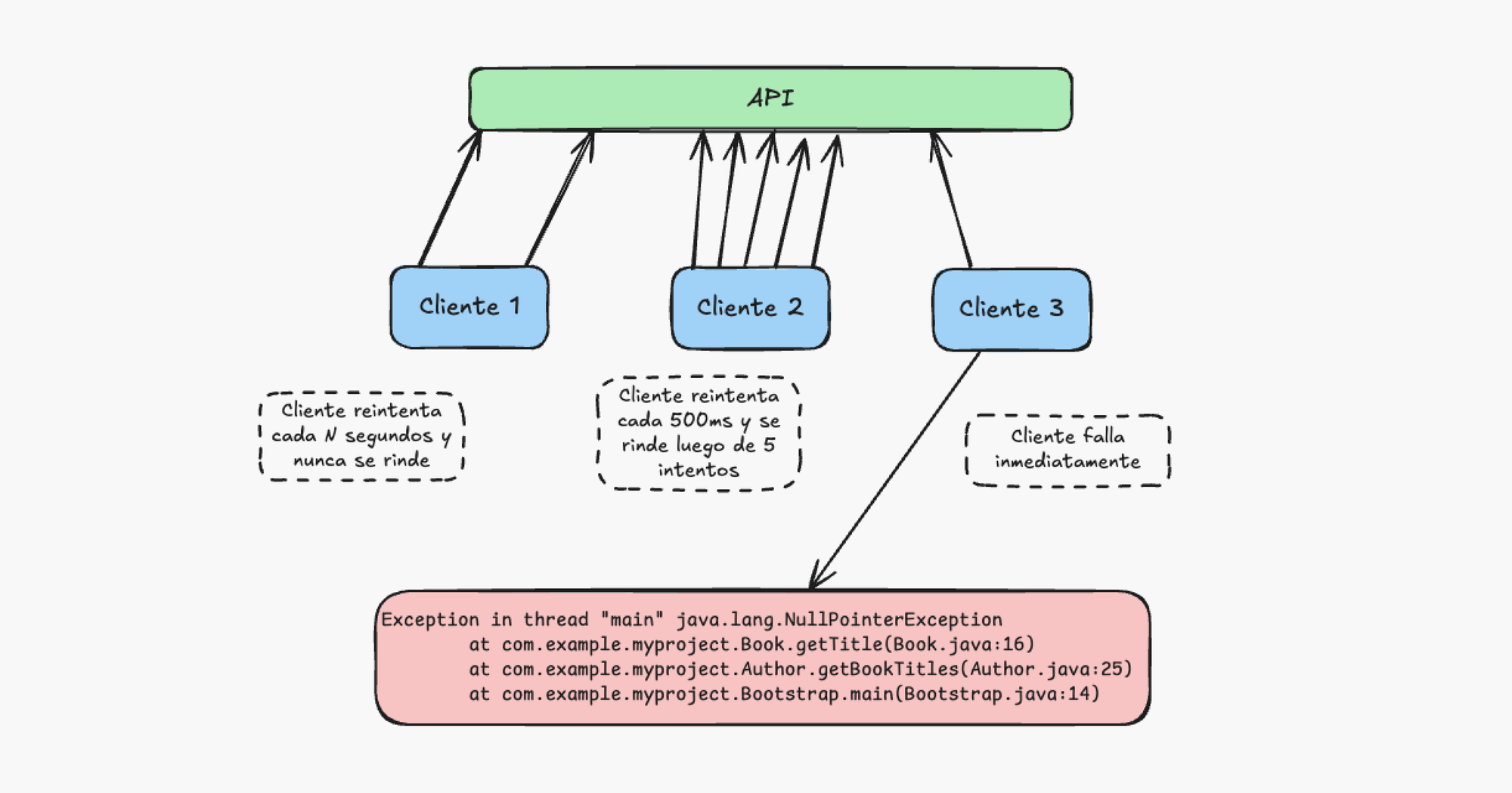
Tener un comportamiento diferente de cada cliente ante errores también se convierte en una fuente de incertidumbre para la propia API que no sabe qué podría ocurrir cuando se presente un problema, por ejemplo, podría recibir DDoS no intencional de parte de sus clientes que están reintentando masivamente mientras otros podrían fallar silenciosamente y todo esto sin posibilidad de reproducir ninguno de estos comportamientos. A esto le sumamos que tener un "capacity planning" y monitoreo se vuelve imposible ya que no sabemos si el tráfico es real, reintentos o loops de error.
2. Previene la toma de decisiones automatizada
Que cada consumidor tenga su propio contrato a veces puede ser inevitable, por más detalle que tengan nuestros mensajes de error, la decisión final de qué hacer está del lado de los consumidores, sin embargo, tener errores bien definidos permite que los consumidores puedan incorporar en su propio código la toma de decisiones automatizada cuando se encuentren con errores.
Esto reduce la carga de troubleshooting de los operadores ya que el propio consumidor de las APIs puede detectar, actuar o filtrar los errores más conocidos sin necesidad de lanzar errores que deben ser revisados y ocupan lugar dentro de las métricas. Volviendo al ejemplo del banco, es como evitar hacer llamadas al centro de atención al cliente para casos triviales.
Estrategias reales para definir errores en contratos
Ahora que entendemos conceptualmente los problemas con los errores mal definidos en contratos, veamos las estrategias más comunes y sencillas que se pueden implementar para mitigarlos:
1. Retryable
Una de las preguntas clave que casi nadie hace al definir errores es "vale la pena reintentar?", cuando una API no define si un error admite un reintento lo que ocurre es que cada cliente decide distinto, algunos reintentan una y otra vez creando una saturación, otros fallan demasiado pronto y otros agregan "sleeps" arbitrarios, o sea los mismos problemas fundamentales de errores mal definidos.
{
"error": {
"code": "DOWNSTREAM_TIMEOUT",
"message": "Payment provider did not respond",
"retryable": true,
"retryAfterMs": 2000
}
}En este ejemplo de contrato, se avisa que se puede hacer un retry y cuanto se debe esperar para el mismo, esto alinea el comportamiento del ecosistema completo.
2. Separar errores de negocio de errores técnicos
Cuando una API quiere comunicar al consumidor que el problema está de su lado se suele usar indiscriminadamente el código 400 para todo, en esta bolsa suelen entrar problemas como usuarios bloqueados, vencidos, o errores de tipeo; con una respuesta genérica de este tipo el cliente no puede decidir nada útil.
Aquí nuestros aliados son los códigos de estado HTTP, que nos dan una gran cantidad de códigos estándar que podemos aplicar en nuestros contratos definiendo errores específicos como:
- 422 Unprocessable Entity: regla de negocio no cumplida.
- 409 Conflict: estado inconsistente / transacción no permitida ahora.
- 400 Bad Request: request mal formado (estructura, tipos).
Por ejemplo podemos tener el siguiente error definido:
responses:
"422":
description: Usuario no habilitado para retiroQue puede ser utilizado para estos casos típicos:
- cuenta bloqueada
- fondos insuficientes
- fuera de horario permitido
3. Definir códigos de error estables
Aparte del código de estado HTTP, podemos ir un poco más lejos y estandarizar el propio mensaje de error que retornamos, normalmente lo que suele ocurrir es que este mensaje es un texto libre del tipo "No se pudo procesar la solicitud" lo cual obliga a los consumidores a parsear un texto cuando quieran accionar en base a este error.
Aquí una mejora que podemos implementar es agregar un errorCode semántico y versionable, independiente del HTTP status, de esta forma los clientes definen su comportamiento en base a contratos y no solo texto. Esto también tiene la ventaja de que permite a los responsables de las APIs a cambiar los mensajes sin modificar el errorCode evitando romper integraciones, mientras que por el lado de la observabilidad, tener un errorCode estable nos da algo sólido que monitorear cuando ocurran rechazos como en el ejemplo que veremos a continuación:

En este schema, definimos un "errorCode" estable y versionado, mientras que el mensaje genérico "message" lo definimos como un simple string, el cual lo podemos cambiar sin afectar a nadie.
ErrorResponse:
type: object
required: [errorCode, message]
properties:
errorCode:
type: string
enum:
- USER_BLOCKED
- INSUFFICIENT_FUNDS
- CARD_EXPIRED
- ATM_NOT_ALLOWED
message:
type: stringEsta API nos retornará el siguiente body, donde podremos utilizar el "errorCode" para tomar una decisión automática sin miedo a que sea cambiado en el futuro, mientras que podremos utilizar el "message" para dar información a nuestro frontend:
{
"errorCode": "USER_BLOCKED",
"message": "El usuario no está habilitado para retiros"
}Este esquema nos muestra una estructura propia (errorCode, message). Eso está bien, pero existe un estándar oficial de internet para esto llamado RFC 7807 (Problem Details for HTTP APIs)
¿Qué es el RFC 7807?
Es un estándar oficial de la IETF (Internet Engineering Task Force) titulado "Problem Details for HTTP APIs". Su objetivo es definir una estructura JSON (y XML) estandarizada para reportar errores en APIs HTTP. En resumen, es un esfuerzo para que los códigos de error tradicionales (4xx, 5xx, etc) puedan proveer información más detallada.
El problema que resuelve es exactamente el que planteamos en este blog: evitar que cada API invente su propio formato de error ({ "error": ... } vs { "message": ... } vs { "code": ... }).
La estructura estándar
El RFC define un Media Type específico: application/problem+json. Cuando una API usa este estándar, la respuesta de error contiene estos campos reservados:
1. type (URI): Una referencia única (idealmente una URL) que identifica el tipo de problema. Sirve como un "código de error" global y puede llevar a una página de documentación.
2. title (String): Un resumen breve y legible por humanos sobre el tipo de problema. No debe cambiar entre ocurrencias del mismo error.
3. status (Number): El código de estado HTTP (ej. 400, 404, 503). Se incluye en el cuerpo por si el cliente o un proxy pierde el acceso al header original.
4. detail (String): Una explicación específica para esta ocurrencia del error. (Ej: "El saldo actual es 10, se requieren 20").
5. instance (URI): Una referencia a la ocurrencia específica del error (útil para guardar como ID de trazabilidad o para indicar qué recurso falló).
Lo mejor del RFC 7807 es que permite agregar campos extra. O sea que es compatible con las estrategias de "retryable" o "validation errors" simplemente agregando esos campos al JSON estándar.
Ejemplo RFC 7807
Así se vería el ejemplo del banco usando RFC 7807:
HTTP/1.1 403 Forbidden
Content-Type: application/problem+json
{
"type": "https://api.banco.com/probs/insufficient-funds",
"title": "Fondos Insuficientes",
"status": 403,
"detail": "Su cuenta posee 500.000 Gs. y el retiro solicitado es de 700.000 Gs.",
"instance": "/transacciones/12345/retiro",
// Campos personalizados (Extensiones permitidas por el RFC)
"balance": 500,
"currency": "PYG",
"retryable": false
}Conclusión
Diseñar los errores como parte integral del contrato es un ejercicio de empatía hacia el desarrollador que consumirá nuestros servicios. Muchas veces olvidamos que el momento más estresante en una integración no ocurre cuando todo funciona bien, sino cuando algo falla. Un contrato que tiene en cuenta y explica detalladamente sus errores deja de ser una simple especificación técnica y pasa a convertirse en un manual de instrucciones que cualquier desarrollador desearía tener. Este manual nos permite no solo "arreglar código", sino también mejorar la experiencia de desarrollo (DX) y generar confianza en nuestra API.
Si le damos la misma importancia a las respuestas exitosas y no exitosas es muy positivo para cualquier arquitectura de microservicios. Como hemos visto, estrategias sencillas como indicar explícitamente si un error es reintentable (retryable), utilizar correctamente la semántica de los códigos HTTP para distinguir fallos técnicos de los de negocio, y establecer errorCodes estables, tienen un impacto directo en la reducción de la carga operativa para todas las partes involucradas.
Estas prácticas permiten a los consumidores automatizar la toma de decisiones, evitan saturaciones innecesarias por reintentos mal gestionados y facilitan el monitoreo. Invertir tiempo en definir el "unhappy path" en nuestros contratos hoy, nos ahorrará incontables horas de soporte, depuración y parches de emergencia mañana.
Como siempre, esperamos que esta publicación les sea de utilidad, y les invitamos a suscribirse para recibir en su correo cada una de nuestros blogs al momento de publicarse, hasta la próxima.