Infraestructura fantasma - Nuestra estrategia para lidiar con este fenómeno

Hoy hablaremos sobre nuestra experiencia con "Infraestructura Fantasma" y les mostraremos un par de tips sencillos que sirven para lidiar con este fenómeno que nos afecta (o afectó) a todos los administradores de sistemas en algún momento de nuestra carrera.
Qué es la infraestructura fantasma
La definición sencilla y muy amplia de infraestructura fantasma es "todo aquel activo del área de TI que ya no se necesita", aquí entran cosas como:
- Máquinas virtuales apagadas que ocupan espacio.
- Buckets S3 con datos obsoletos.
- Réplicas extra de microservicios.
- Imágenes Docker muy antiguas.
- Repositorios o ramas no utilizadas.
- Tablas y bases de datos sin uso.
- Jobs CI/CD obsoletos.
Estos son los componentes que se pueden identificar rápidamente y que se pueden eliminar sin problema, pero también hay otros tipos de infraestructura fantasma más difíciles de controlar.
Para estos tenemos una nueva definición: "aquellos activos del área de TI que se usan mal".
La verdadera infraestructura fantasma
Ya con la definición nueva "aquellos activos del área de TI que se usan mal" podemos detectar cosas como:
- Clusters (kubernetes, RDS, VMWare) sobre dimensionados.
- Servicios deprecados con soporte extendido más caro.
- Usuarios innecesarios en servicios que cobran por seats.
- Servicios que se utilizan poco.
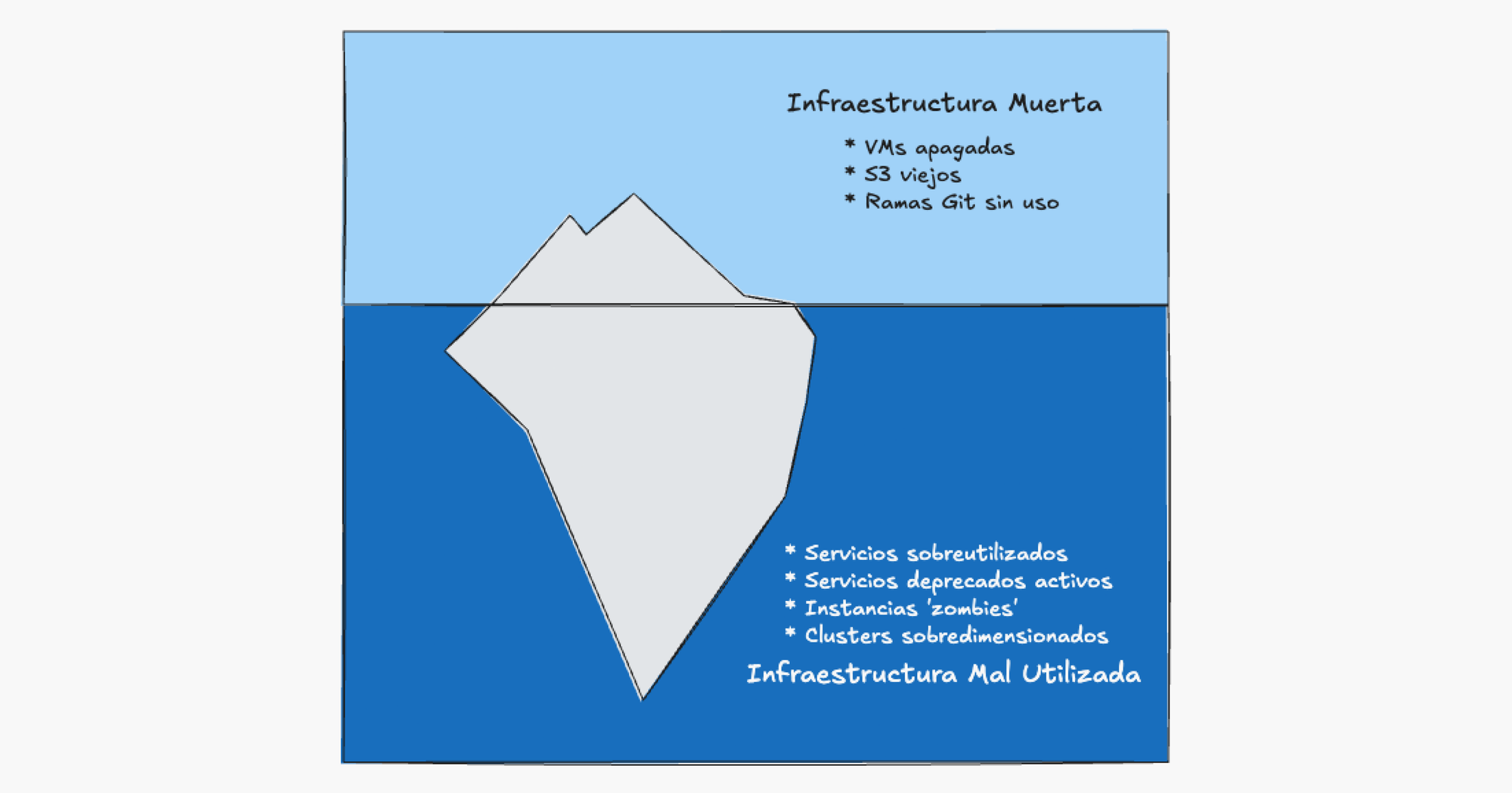
Decimos que esta es la verdadera "infraestructura fantasma"; no son simplemente servicios o recursos que están "muertos" y no se utilizan que pueden ser detectados y eliminados fácilmente, sino que están "vivas" pero no pueden ser individualizadas fácilmente ya que normalmente dependen de otros componentes que sí están en uso o son necesarios y hacen que el panorama real se poco claro.
Nuestra experiencia con el fantasma AWS Aurora
Tomemos como ejemplo el servicio de AWS Aurora, que utilizamos en fintech.works y se terminó convirtiendo en un "fantasma". En nuestro caso, creamos un cluster de base de datos utilizando Aurora como backend para poder medir el rendimiento de una aplicación mediante pruebas de stress. En su momento Aurora nos permitió escalar rápidamente el servicio hasta poder encontrar todos los cuellos de botella posibles y como ventaja final, nos ofrecía la posibilidad de escalar automáticamente (hacia abajo) para reducir costos.
Inicialmente el ajuste automático funcionó muy bien, el cluster Aurora crecía automáticamente a medida que hacíamos pruebas sobre el ambiente y luego escalaba automáticamente a 1 réplica en periodos de poca actividad, pero luego de unos meses se logró instalar el sistema en la infraestructura del cliente quedando nuestro ambiente de desarrollo con mucha menos actividad.
En este punto el "fantasma" apareció y empezó a crecer, si bien el cluster tenía una sola réplica, el costo mensual de esta réplica (86,4 dólares) era mucho mayor al de la instancia más pequeña de PostgreSQL en RDS (11,5 dólares) y mucho más que tener una simple instancia con PostgreSQL instalada manualmente (6 dólares).
Hasta aquí se nota como el fantasma se puede esconder detrás de hechos reales que parecen inofensivos, como por ejemplo el hecho de que el cluster de Aurora estaba en su tamaño mínimo, por lo tanto el costo era óptimo para nuestro caso, sin embargo, la realidad era más compleja, ya que con la nueva situación de nuestro ambiente de desarrollo, podríamos estar reduciendo el costo en un 94% mudandonos a una solución un poco más compleja pero más apropiada para nuestra carga.
Por qué es tan común la "infraestructura fantasma" en TI
Luego de detectar el sobrecosto de Aurora nos pusimos a mirar con detalle nuestro proceso de "limpieza" de infraestructura para tratar de ajustarlo y evitar que vuelva a ocurrirnos algo así. Aquí vimos que si bien nuestro sistema de limpieza sigue un estándar bien conocido por los que alguna vez trabajamos en TI, aún había un hueco por el que se podían filtrar este tipo de problemas.
En resumen, nuestro sistema de limpieza consiste en un inventario anual, donde todos los activos de infraestructura son buscados, encontrados y justificados en base a qué proyectos sirven.
Por ejemplo, si en nuestro inventario aparece listada una máquina virtual X, procedemos a ubicarla dentro de la cuenta AWS y anotamos que en la fecha actual la máquina virtual X está dando servicios al proyecto X que aún sigue activo, como podrán notar, este proceso se encarga correctamente de aquellos componentes huérfanos y que pueden ser dados de baja sin afectar a nadie, por ejemplo, si encontramos un cluster dedicado a un proyecto que ya terminó de desarrollarse, lo podemos dar de baja y anotarlo como "deprecado".
El problema es que para el primer caso de la máquina virtual X no se tuvo en cuenta que el proyecto X que aún sigue activo, ya no necesita 16GB de RAM para su suite de tests y que con un poco más de 2GB de RAM es suficiente para que siga operando. Aquí vemos que para lograr un inventario correcto, es necesario un proceso mucho más profundo de búsqueda de información que no solo implica involucrar a un desarrollador del proyecto (lo cual cuesta tiempo y por ende dinero) que tal vez ni esté al tanto del performance que necesita su ambiente de desarrollo, sino un cambio total de la forma de hacer no solo el inventario sino de manejar la limpieza de nuestros activos.
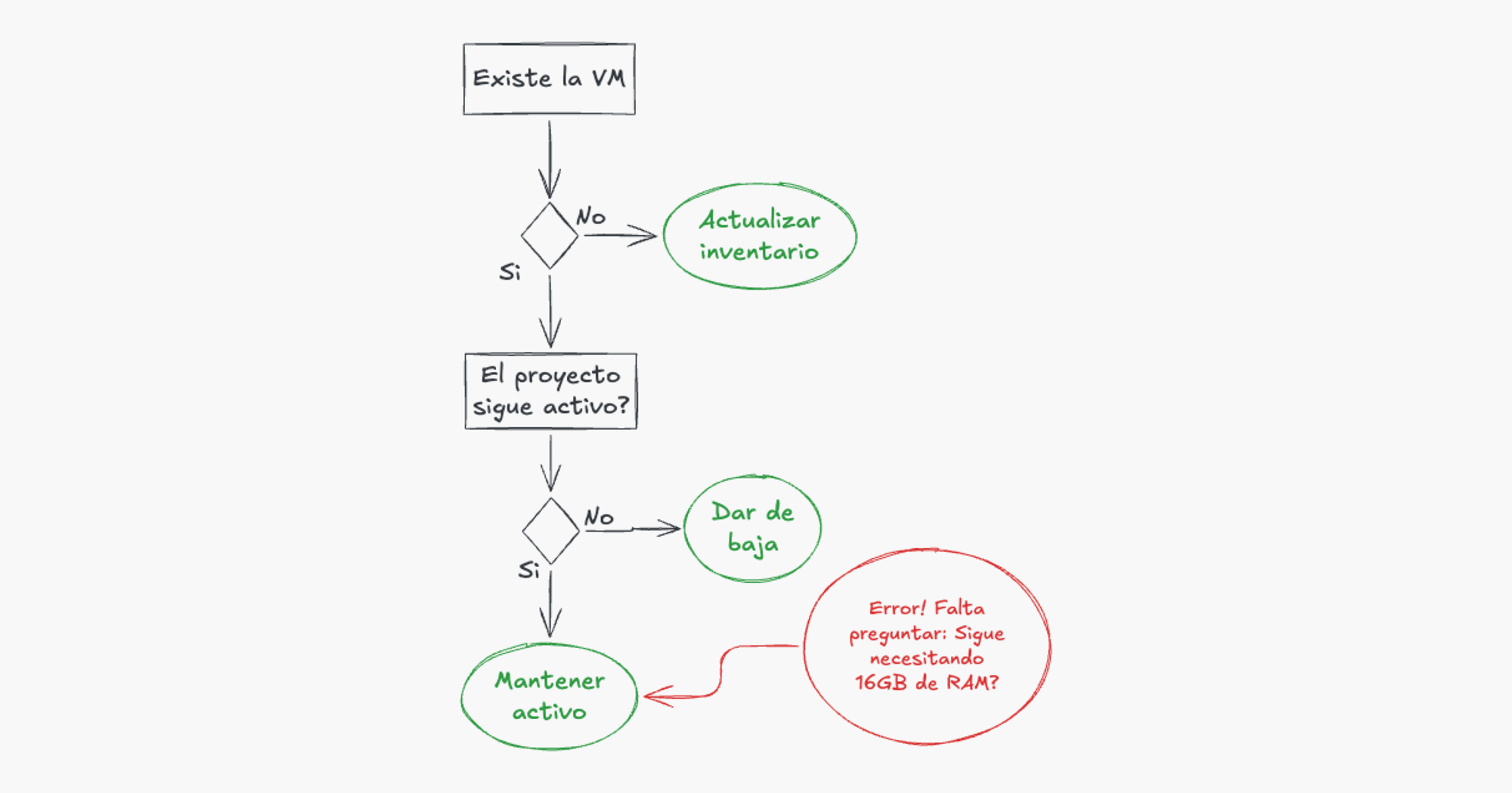
Hasta aquí el problema es evidente, los requisitos cambian, pero no siempre podemos estar al tanto de los mismos, pero por qué ocurre el problema? y por qué hay ciertas áreas que no padecen de estos mismos problemas?
El problema de fondo: La falta de ciclos naturales en TI
Si nos ponemos a investigar sobre otras áreas de trabajo humano, por ejemplo la agricultura o manufactura, donde se maneja una gran cantidad de inventario (semillas, componentes, maquinarias, etc.), notamos que estas no sufren del mismo problema de "acumulación" de activos ya que se rigen por un ciclo natural que les obliga a deshacerse del inventario extra obligatoriamente luego del final de cada "ciclo natural", aquí los ciclos naturales definen cómo, cuando y qué plantar (usando el ejemplo de la agricultura), y al terminar su ciclo de cosecha, se hace una limpieza total de los campos, y se empiezan a preparar las maquinarias para el siguiente ciclo, lo que obliga a deshacerse de todo lo que no será útil para el siguiente ciclo de cultivo, y así sucesivamente.
En manufactura pasa algo similar, cuando una fábrica termina de producir un producto en particular, debe "reconfigurarse" para empezar a producir otro producto y esto implica dar de baja todo lo que no sea de utilidad para el siguiente ciclo.
En ambos casos este ciclo natural se complementa con un incentivo económico, ya que este obliga a usar correctamente las herramientas y recursos que se tienen a mano e incentiva a dar de baja todo aquello que no sea de utilidad.
Sabiendo esto, volvamos al área de TI, y aquí nos damos cuenta que esta área no tiene ciclos naturales, al contrario, hay cosas que parecen durar para siempre, así que aquí la situación se presta y es propicia para los "fantasmas", si no hay ningún ciclo o incentivo para deshacerse de ellos, y existen recursos y tiempo para mantenerlos vivos, lo que ocurre es que perduran y se vuelve muy difícil deshacerse de ellos.
Es posible crear ciclos naturales en TI?
Esta es la pregunta clave del problema, y la respuesta rápida es "si, es posible", pero no nos adelantemos a la conclusión y primero veamos algunos problemas especiales y ejemplos que se tienen en el área de TI.
Para empezar, como dijimos en la sección anterior: "En TI las cosas parecen durar para siempre", y esto ocurre porque en TI damos soporte o utilizamos productos que no tienen ciclos de vida definidos y si los tienen estos no coinciden entre sí por lo que se vuelve muy poco probable que invirtamos tiempo en tratar de acomodarlos. Por otro lado está el tema de las dependencia entre sistemas con ciclos de vida distintos, que hacen que el cleanup de los recursos no dependa de un solo proyecto o servicio.
Pongamos por ejemplo una situación bien sencilla: un servidor de base de datos que se convirtió en fantasma siguiendo esta cronología:
- Se crea un servidor de base de datos PostgreSQL con la versión 9.6 para dar servicio a una aplicación Java versión 8 (le llamamos X).
- Luego de un año aparece otra aplicación Java versión 17 (llamada Y) y se usa la misma base de datos ya que la aplicación X está con poca actividad.
- Un año más tarde se agrega otra base de datos de una aplicación Java versión 19 (llamada Z) en el mismo servidor.
- Un par de meses después se intenta actualizar la versión del PostgreSQL a la 17, tanto Z como Y funcionan correctamente con esta versión, pero la aplicación X no lo hace, se decide no actualizar.
- En una reunión con los responsables de X, Y y Z se llega a la conclusión que la aplicación X ya no se actualizará por falta de recursos, por lo que se debe hacer una migración (costosa) de las bases de datos de Y y de Z a otros servidores que si se puedan actualizar.
Viendo esta cronología completa el problema es evidente: "El servidor de base de datos se utilizó demás", y los proyectos nuevos quedaron atados a este componente y luego no pudieron avanzar.
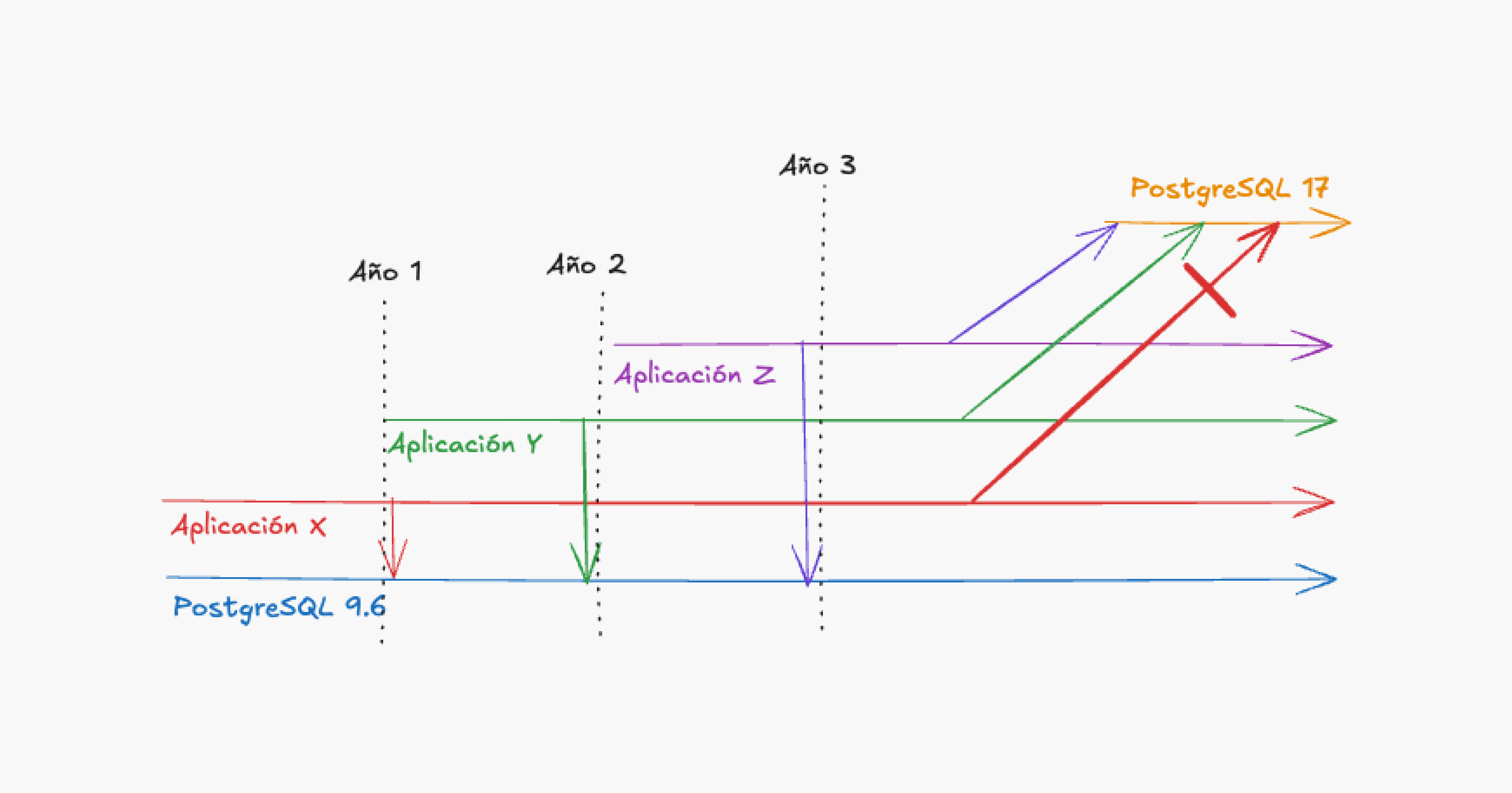
Pero como dice la frase "Con el diario del lunes es fácil", este problema solo lo pudimos detectar ya al final del ciclo de vida del componente y luego de crear problemas costosos.
Sabiendo esto es que proponemos la siguiente solución: ponerle fecha de expiración a todo.
Recursos que nacen con fecha de expiración
Muchos de ustedes ya se imaginarán a donde queremos llegar con lo de "fecha de expiración para todo", pero para los que no lo hacen la idea es la siguiente:
Si al ejemplo de la sección anterior le aplicamos el principio de "fecha de expiración" al servidor de la base de datos, el problema no hubiese ocurrido. En ese caso, al momento de crear el proyecto X, podríamos haberle puesto una fecha de expiración al mismo, por ejemplo de 1 año, y luego de haber pasado este tiempo, marcarlo de alguna forma para que no se siga innovando sobre el mismo y sus recursos no sean utilizados para otros fines.
Esta "marca" o "tag" para evitar uso nuevo de un recurso no es nada nuevo, de hecho es utilizado por kubernetes para marcar nodos como "unschedulable" lo que significa que pods nuevos ya no serán desplegados en ese nodo, sin embargo, aquellos pods que ya se encuentran corriendo en el mismo podrán seguir operando sin interrupción.
Volviendo al ejemplo de la base de datos, si al servidor PostgreSQL lo hubiésemos acordonado luego de 1 año, la aplicación Y ya no lo iba a poder utilizar, por lo que tendría que haberse desplegado en un servidor independiente, y lo que es más importante, más actualizado. Lo mismo hubiese ocurrido con la aplicación Z, que utilizaría su propio servidor que podría ser actualizado de manera independiente sin preocuparse de la interdependencia con la aplicación Y.
Como podemos ver, esta estrategia de "acordonar" recursos puede generarnos gastos extra ya que en nuestro ejemplo en vez de tener un solo servidor de base de datos que da servicio a las tres aplicaciones, tendríamos 3 servidores nuevos cada uno con su versión diferente con lo cual estaríamos aumentando la complejidad de nuestro sistema en general, sin embargo, debemos tener en cuenta que estos 3 servidores nuevos son independientes, por lo que se pueden optimizar individualmente y hasta podríamos llegar a lograr que el costo de los tres servidores sea inferior que tener uno solo pero sin optimizar.
En cuanto a la complejidad, no podemos negar que tener que administrar más recursos (en cantidad) a los que tendríamos si todo estuviese consolidado en menos componentes es más complejo, así que para cada caso hay que tener en cuenta este punto, para no complicarnos la vida aplicando esta técnica en casos en los que podría causar más problemas que facilidades.
Estrategias para acordonar recursos
Ahora que sabemos que "acordonar" recursos luego de cierto tiempo es una estrategia válida para mitigar estos problemas, veamos algunas formas prácticas y un poco más trabajadas para llevarlo a cabo sin demasiada complejidad.
1. Etiquetar al crear
La forma más sencilla es implementar una política que diga que al momento de crear un recurso, a este se le debe agregar un tag "expiration_date" y otro llamado "status". Este tag será leído por un script de mantenimiento que puede correr cada 1 mes y cambiará el tag de los recursos vencidos a status: cordoned.
Este mecanismo luego puede ser aprovechado por nuestros pipelines CI/CD que lo utilizarán para evitar que servicios nuevos sean desplegados en ellos.
2. Aislar en IaC
Si utilizan Terraform o CloudFormation, una buena práctica es separar los recursos "legacy" en archivos de estado o stacks diferentes. Cuando un proyecto cumple su ciclo, su infraestructura se mueve a un repositorio de "mantenimiento". Los nuevos proyectos no tienen acceso a importar módulos de ese repositorio, forzando la creación de recursos frescos y optimizados para las necesidades actuales.
3. Time-to-Live (TTL) en ambientes no productivos
Para el caso específico de entornos de desarrollo o pruebas (como el caso de nuestro cluster de Aurora), la estrategia debe ser aún más agresiva: la infraestructura debe nacer con una fecha de muerte programada. Herramientas como cloud-nuke o scripts lambda pueden eliminar automáticamente recursos de desarrollo que no tengan un tag de keep-alive renovado explícitamente cada semana. Esto evita que un entorno de pruebas de stress se convierta en una base de datos "eterna" por olvido.
Conclusión: Cambiando la mentalidad de "Mascotas" a "Cosechas"
La infraestructura fantasma no es solo un problema técnico o de presupuesto, es un síntoma de una cultura de TI que trata a los servidores y servicios como activos permanentes (mascotas) en lugar de recursos temporales y cíclicos (cosechas).
En nuestra experiencia con el cluster de Aurora, el error no fue técnico ya que la base de datos funcionaba perfecto, el error fue de gestión del ciclo de vida. Si hubiésemos aplicado el concepto de "fecha de expiración" desde el día uno, ese cluster habría sido acordonado al finalizar la fase de pruebas de stress. El equipo de desarrollo se habría visto obligado a levantar una instancia pequeña de PostgreSQL para el mantenimiento diario, ahorrándonos cientos de dólares al año y evitando la dependencia técnica.
La invitación final de este blog es a que revisen su inventario no solo buscando qué apagar hoy, sino pensando en cómo impedir que lo que enciendan mañana se convierta en el fantasma del futuro. Poner fecha de caducidad a la infraestructura nos da la libertad de innovar sin arrastrar el peso muerto del pasado.
Empiecen por lo simple: la próxima vez que levanten un servidor, pregúntense "¿Cuándo debe morir esto?" y anótenlo en un tag. Su presupuesto (y su salud mental) se lo agradecerán.