Integrando monorepos con AWS Codepipeline

Contexto
En el 2024 nos tocó desarrollar una Proof of Concept para un cliente que mantiene toda su arquitectura de desarrollo sobre servicios de AWS, los relevantes para esta historia son:
- CodeCommit: Repositorio de código.
- CodeBuild: Sistema de integración continua as a service.
- CodePipeline: Orquestador de CI/CD.
- ECS: Los microservicios se despliegan sobre un cluster ECS.
El producto del cliente al cual debe dar servicio la PoC consiste en un sistema de pagos con arquitectura de microservicios, donde cada microservicio cuenta con su propio repositorio en CodeCommit.
Los cambios de código siguen un pipeline de CI/CD sencillo:
- Se hacen cambios al código de un microservicio y se pushean a una rama del repositorio
- El commit sobre la rama activa a un pipeline de CodePipeline
- Este pipeline activa el proyecto de CI del microservicio definido en CodeBuild
- CodeBuild construye y prueba el microservicio, genera los artefactos y la imagen Docker
- CodePipeline termina con un stage que despliega la imagen Docker en un service de ECS
Desarrollo del PoC
Al ser un Proof of Concept, tendríamos que utilizar el mismo esquema de desarrollo y reutilizar algunos de sus microservicios con ciertas modificaciones.
Y debido a que la PoC debía ser autocontenida y con una gran cantidad de commits dependientes, se decidió elegir el esquema de monorepo para el proyecto.
Las ventajas de los monorepos para este tipo de proyectos incluyen:
- Colaboración simplificada: ya que la PoC contiene módulos que interactúan entre sí de forma muy cercana y los developers trabajan sobre más de un módulo a la vez.
- Commits cross-modulos: el ritmo de desarrollo implica hacer commits que afectan a varios módulos a la vez, con monorepos logramos mejor consistencia.
- Dependencias consistentes: todos los módulos tienen dependencias comunes almacenadas en el repo.
Una vez que tuvimos nuestros módulos compilando en el monorepo, y funcionaban correctamente en el cluster ECS, nos pasamos al proceso de despliegue automatizado, esto es, agregar la última stage de deploy al pipeline, y aquí nos encontramos con el problema.
El problema
Nos dimos cuenta que nos hacía falta una pieza clave para el despliegue. Esta pieza es un archivo conocido como `imagedefinitions.json` el cual contiene una lista de imágenes docker con sus tags nuevos, en el proceso de despliegue se combinan los tags que están en el archivo `imagedefinitions.json` con los del task-definition de un service en particular.
El problema es que el archivo `imagedefinitions.json` solo puede contener containers que ya existan en el task-definiton del service en particular, lo cual no es posible en nuestro caso ya que nuestra compilación genera el archivo para todos los services del repo, y los microservicios se despliegan en Services diferentes.
En resumen, para N task-definitions, necesitamos N archivos imagedefinitions.json.
Este problema nos dió un objetivo fácil de enunciar:
- "Encontrar un mecanismo para generar un imagedefinitions.json para cada microservicio"
La solución
Luego de probar variaciones del pipeline de CI/CD, nos quedamos con el siguiente mecanismo: Dividimos el proceso de build en dos pipelines, una de ellas se ejecuta cada vez que hay cambios en el repo y se dedica a construir la imagen Docker, luego existe otra por cada microservicio, la cual se ejecuta cada vez que se encuentra una nueva imagen Docker del microservicio, y se dedica exclusivamente a generar el archivo imagedefinitions.json y desplegar el mismo en el cluster ECS.
En el siguiente diagrama se enumeran y explican los pasos que sigue un cambio en código hasta llegar al ECS:
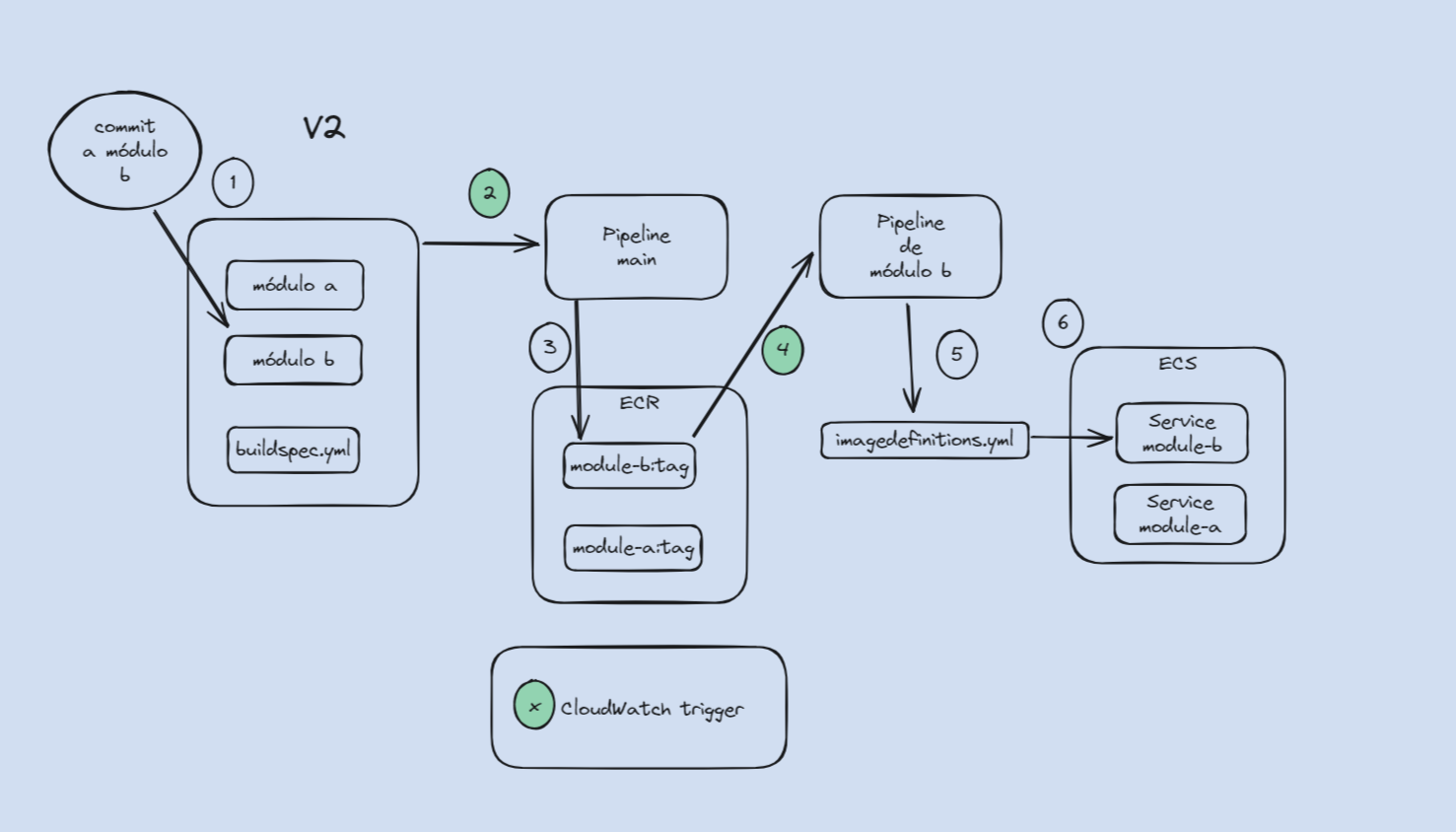
1. El pipeline empieza cuando un developer integra un commit a la rama main, esto activa el pipeline main.
2. Este pipeline construye todo el proyecto en el buildspec general con `./gradlew assemble`, esto genera artefactos que se usan en la siguiente stage del pipeline.
3. Luego se generan las imágenes Docker usando los artefactos y se suben al ECR.
4. Las imágenes Docker en el ECR activan pipelines dedicados a cada módulo.
5. Estos pipelines generan el imagedefinitions.json para cada microservicio.
6. Se invoca el stage "Deploy" de cada pipeline y se despliega en la imagen Docker en el ECS con el imagedefinitions.json del paso anterior.
Deuda técnica
Del esquema anterior quedaron los siguientes puntos de deuda técnica:
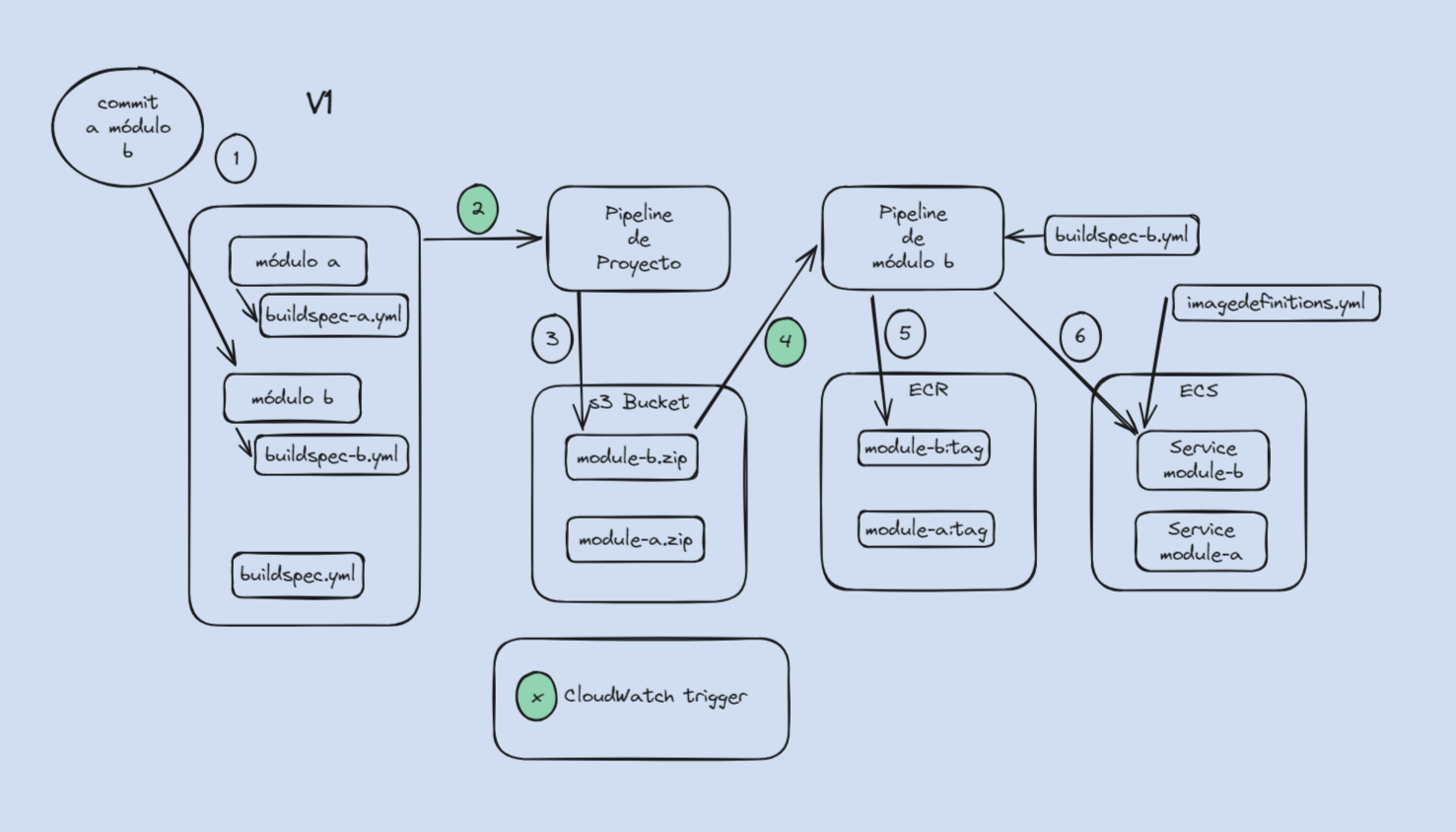
- Cada vez que se hace cambio sobre un microservicio, se deben compilar los demás debido a las dependencias:
- Esto se soluciona haciendo un refactor de dependencias y moviendo la compilación del módulo a su propio pipeline. Con este esquema, el pipeline principal solo se limita a detectar los microservicios que cambiaron y envía el código fuente como .zip a través de AWS S3 a su pipeline específico, el cual tiene su propio archivo buildspec.yml. De esta forma, el pipeline principal se ejecuta cada vez que hay un cambio, pero al ser solo un chequeo sin compilación, su duración es muy corta. Este esquema se puede ver en el siguiente diagrama.
Finalmente
Les agradecemos el tiempo, esperamos que la solución que implementamos les sea útil y como siempre les invitamos a ayudarnos de esta forma:
- Dejando feedback.
- Suscribiéndote al blog.
- Dejando ideas sobre futuros temas.
Hasta la próxima!