Lecciones de Aviación para DevOps: Usando PIOSEE para Manejo de Incidentes


Tarde o temprano a los informáticos nos toca enfrentarnos a una crisis, que puede ser un sistema que cae de la nada, una vulnerabilidad crítica que se descubrió en la madrugada, o una pipeline que falla justo cuando más se la necesita. ¿Cómo respondemos cuando todo lo que parecía estar bien de repente se vuelve incierto?
Cuando hablamos de crisis inesperadas existe un área donde el manejo de las mismas es una ciencia con todas las letras, aquí las consecuencias de responder mal implican la pérdida de vidas humanas y daños materiales enormes. El área de la que estamos hablando es la aviación.
En este mundo donde un piloto puede jubilarse sin haber sufrido ningún accidente, el entrenamiento para el "worst case scenario" es constante, como si lo estuviesen esperando todos los días, ya que cuando realmente ocurra la respuesta debe ser inmediata, clara y sin margen de error. También es en estas situaciones donde se definirá la reputación del piloto, cuando uno hace bien las cosas en una situación cuya probabilidad de ocurrir es de 0.000001% se comprueba que es un profesional, no solo un piloto.
En DevOps y Operaciones sucede algo similar. Podemos automatizar procesos, monitorear todo y planificar nuestros cambios, pero siempre habrá ese momento donde algo falla. Y es ahí donde se ve realmente la madurez de un equipo: no en los días tranquilos, sino en la tormenta.

Esta vez vamos a explorar cómo uno de los modelos de toma de decisiones que utilizan los pilotos, conocido como PIOSEE, puede servir como herramienta para navegar situaciones de crisis en las áreas de tecnología.
¿Qué es PIOSEE?
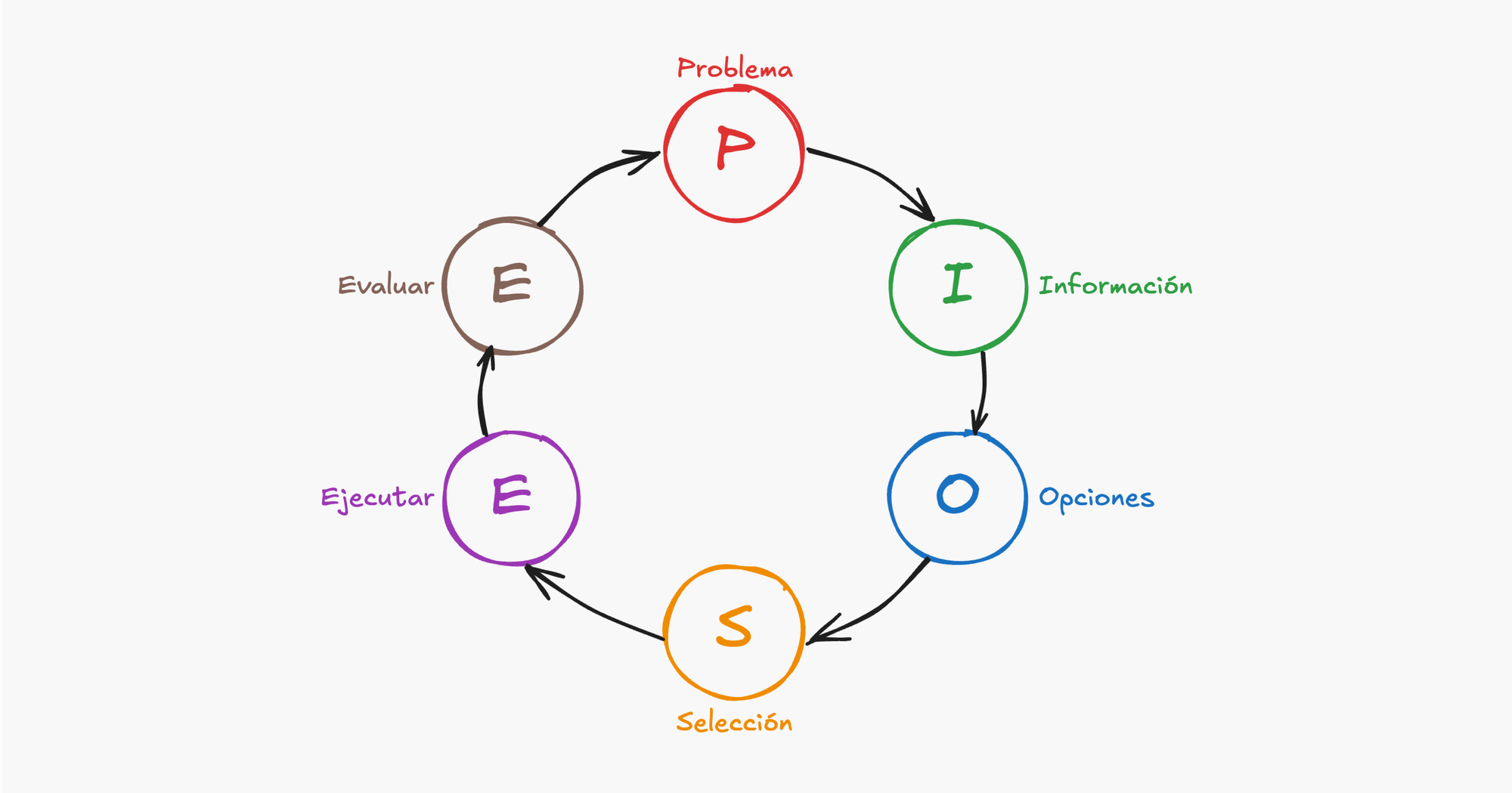
PIOSEE es un modelo de toma de decisiones utilizado por pilotos de avión para evaluar y responder a situaciones complejas bajo presión de manera estructurada y repetible. Cabe destacar que PIOSEE no es el único modelo que existe, también están FORDEC y T-DODAR pero todos son prácticamente lo mismo con términos diferentes. En el caso de PIOSEE el acrónimo significa:
• P - Problema
• I - Información
• O - Opciones
• S - Seleccionar
• E - Ejecutar
• E - Evaluar
Cada uno de estos términos es un paso que debe ejecutarse en orden, más adelante veremos un ejemplo de como hacerlo en situaciones reales.
En la cabina, este marco ayuda a los pilotos a no tomar decisiones apresuradas o incompletas. En el área de operaciones —donde cae la responsabilidad de los incidentes, caídas y cambios críticos—, este modelo puede aportar estructura y claridad en momentos donde más se necesitan.
¿Por qué es relevante en Operaciones?
Los equipos de operaciones son los que tienen la responsabilidad de responder a estos problemas:
- Una aplicación que deja de funcionar durante un pico de tráfico.
- Vulnerabilidades de seguridad encontradas minutos antes de un despliegue.
- Señales contradictorias de herramientas de monitoreo.
- Presión de gerencia o clientes para actuar rápidamente.
En estos escenarios, una toma de decisiones sin un marco o estructura lleva siempre a:
- Arreglos que rompen otros sistemas.
- Rollbacks prematuros sin entender la causa raíz.
- Mala comunicación y trabajo poco eficiente en equipos.
- Decisiones tomadas por intuición o jerarquía, no por evidencia.
En estas situaciones es donde PIOSEE muestra su utilidad porque es aquí donde proporciona a los equipos un modelo mental compartido para abordar estas situaciones con orden.
El marco PIOSEE aplicado
Ahora que sabemos los pasos y para qué sirve el modelo, veamos en detalle cada paso:
1. Problema – ¿Qué está pasando?
Este es el primer paso y tiene como objetivo identificar el problema. Esto parece un objetivo muy escueto ya que normalmente los problemas son evidentes como "la app no funciona" o "el clúster quedó sin RAM", pero casi siempre estos son síntomas.
El proceso de obtener problemas a partir de síntomas puede ocurrir de forma intuitiva en muchos informáticos, especialmente cuando conocemos bien los sistemas que administramos, pero que acostumbrarnos a que esto ocurra de forma intuitiva y hasta se puede decir "en segundo plano" nos puede meter en problemas muy graves, por ejemplo, si volvemos al mundo de la aviación y como pilotos alguna vez nos piden que esperemos para aterrizar por que hay una tormenta en la pista, nuestro problema real no es la tormenta o aterrizar con turbulencia, el problema real es que si espero unos minutos más ya no tendré combustible para desviar a otro aeropuerto como siempre lo hice pero en un avión más pequeño.
La clave aquí está en no solo identificar el problema sino también una proyección del mismo en el futuro donde puede ocurrir algo más grave, entonces, unas alertas cotidianas de "RAM al 90%" que nunca causaron problemas se pueden convertir en una catástrofe a fin de mes cuando se despliegue un servicio nuevo.
Entonces nuestra recomendación para este primer paso: escribir el problema y decorarlo con preguntas clave como:
- ¿Qué disparó este problema?
- ¿Qué sistemas afecta?
- ¿A qué usuarios afecta?
- ¿Es un síntoma de algo más grande?
Al responder estas preguntas surgirá intuitivamente el problema real y una vez que lo tengamos identificado pasamos al siguiente paso.
2. Información – ¿Qué sabemos?
Una vez que identificamos el problema actual o el más grave que está detrás empezamos a recolectar datos sobre el mismo, por ejemplo: logs, métricas, trazas, páginas de estado, cambios recientes.
Aquí las preguntas claves que nos ayudan son:
- ¿Qué cambió recientemente?
- ¿Qué sistemas están sanos o degradados?
- ¿Qué están experimentando los usuarios?
En esta etapa es muy importante que evitemos hacer suposiciones, ya que estamos armando los cimientos de nuestra toma de decisiones, cualquier suposición nos puede llevar a que todo el proceso pierda utilidad. Solo tendremos en cuenta hechos reales.
3. Opciones – ¿Qué podemos hacer?
Completar los pasos de "problema" e "información" nos permitirá armar una lista de qué soluciones podemos intentar, tenemos que anotarlas todas incluso las menos cómodas o riesgosas.
Ejemplo:
- ¿Reiniciar el servicio?
- ¿Hacer rollback del último despliegue?
- ¿Redirigir tráfico a otra región?
La clave en este punto es considerar los pros y contras de cada una de las opciones, comparando el riesgo vs beneficio de todas.
4. Seleccionar – ¿Qué opción elegimos?
En esta etapa tomamos una decisión y optamos por ejecutar una de las alternativas que aparecieron en el paso de "opciones".
Las preguntas que nos ayudarán a elegir son:
- ¿Qué opción resuelve el problema raíz más rápido?
- ¿Cuál trae menos riesgo?
- ¿Cuanto tiempo durará la solución?
- ¿Quién debe aprobar o estar informado?
En este paso es muy importante documentar por qué se eligió esa opción. Esto mejora la responsabilidad y el aprendizaje posterior.
5. Ejecutar – Hacerlo.
Una vez elegida la solución es hora de implementarla, un tema importante en este paso es anotar los pasos que llevamos a cabo y problemas que puedan surgir, esto nos servirá para armar un postmortem más completo cuando termine el incidente.
Es buena idea usar checklists o runbooks si están disponibles y de vuelta anotar cualquier desviación para mantenerlos actualizados. Otra buena idea es coordinar el incidente en un canal dedicado (Slack, Teams, etc.) de esta forma todo el proceso incluyendo las comunicaciones quedará documentado.
6. Evaluar – ¿Funcionó?
Una vez aplicada la solución, no asumas que el problema se resolvió, al contrario, asume que el problema no se resolvió y solo cambiaron los síntomas, esto ayuda a poner a nuestro cerebro en modo "escéptico" con lo que seremos menos propensos a interpretar mal los síntomas.
Preguntas clave para hacernos en esta etapa:
- ¿Se resolvió el problema original?
- ¿Se generaron nuevos problemas?
- ¿Qué dicen los usuarios o las herramientas de monitoreo?
Este es el paso final, así que si no se pudo resolver el incidente, se resolvió parcialmente, o si no estamos del todo contentos con el resultado, se inicia otro ciclo PIOSEE.
Recomendaciones para aplicar en todos los pasos
A medida que ejecutemos cada paso es muy importante tratar de aplicar estos comportamientos en cada uno:
- Pedir y dar opiniones: los buenos equipos deben estar acostumbrados a que en situaciones críticas, los encargados de tomar decisiones pidan opiniones por más que estén seguros del problema y los miembros del equipo las den sin miedo, ya que en estas situaciones es muy frecuente el fenómeno del efecto túnel en el que caemos cuando tenemos que lidiar con muchas alertas y responsabilidades al mismo tiempo. Tener esta cultura de "no confiar en un cerebro estresado por más que sea el mío" es algo que ha evitado miles de accidentes.
- Delegar responsabilidades no tareas: en los momentos críticos es normal que la carga de tareas del equipo aumente considerablemente sumándole el hecho de que estas tareas no son las que hacemos en el día a día, no nos conectamos a mirar el log de un componente oscuro del sistema todos los días, lo que suele ocurrir es que estas tareas no se distribuyen correctamente al equipo, quedando a cargo del primero que las recibió, normalmente el jefe o el más experimentado, provocando una sobrecarga. En el mundo de la aviación se asignan "responsabilidades" en vez de "tareas", por ejemplo, "tú te encargas de la comunicación" antes que "llama a la torre y diles que nos redirijan" o "tu te encargas de volar el avión" en vez de "tu controla la altura y yo la velocidad", es buena práctica implementar esto adaptándolo a nuestra situación real, distribuyendo la carga entre el equipo.
- Mantener un mapa mental de equipo: volviendo al fenómeno del "efecto túnel", es común que esto cause un aislamiento entre los miembros del equipo, no nos referimos a que no se ven entre sí, sino que tienen una percepción distinta de la realidad entre ellos, por ejemplo puede ocurrir que ante un problema con un sistema del backend, el DB admin esté cortando conexiones a la base de datos que el equipo de frontend está iniciando para aplicar querys que solucionarán el problema, aisladamente son tareas de buena fe, pero aplicadas fuera un modelo situacional compartido y de forma independiente terminan empeorando la situación. Cuestiones como esta son muy comunes cuando se arman equipos (que raramente trabajan juntos) al momento de que ocurre un incidente, en el mundo de la aviación esto es aún más severo ya que este aislamiento ocurre incluso entre pilotos que llevan años trabajando juntos y en el mismo avión. Es importante que todos los miembros del equipo estén al tanto de este fenómeno pero más importante aún que los gerentes o jefes de área no solo entiendan el concepto sino que estén acostumbrados a lidiar con el mismo.
CRM (Crew Resource Management)
Estos comportamientos, fenómenos y formas de mitigarlos forman parte de un todo más grande que es la disciplina de CRM (Crew Resource Management) también utilizada en aviación, esta tiene como objetivo mejorar la seguridad de los vuelos pero poniéndole foco a temas humanos como la comunicación el liderazgo la toma de decisiones, etc.
A simple vista puede parecer un simple marco para manejo de personas, algo que se puede condensar en una simple presentación del área de recursos humanos, pero que en realidad con los años y estudios científicos sobre situaciones reales se comprobó que efectivamente mejora la capacidad de resolver problemas y por ende la seguridad. Tan comprobada está la efectividad de esta herramienta que actualmente el entrenamiento periódico de CRM es un requisito obligatorio para todos los pilotos que trabajan bajo agencias regulatorias como la FAA (Federal Aviation Administration).
Al ser una disciplina en sí es imposible discutirla en un simple blog, por lo que nos limitamos a listar las buenas prácticas más importantes y que normalmente se consideran como la punta del iceberg del CRM.
El rol del "Comandante del Incidente"
Hasta ahora hablamos sobre PIOSEE y nos limitamos a explicar qué es y cómo funciona, sin embargo todavía no especificamos quién debe aplicarlo cuando ocurre un incidente, es aquí donde la disciplina de CRM nos muestra el rol de "Comandante de Incidente", su naturaleza queda perfectamente definida con la siguiente frase: "Mi responsabilidad no es arreglar el incidente, es manejar la respuesta". Esta frase es muy clara para mostrar su responsabilidad, pero en cuanto a las tareas o herramientas específicas que debe tomar, estas dependen de cada área, para lo que nos interesa, en el área de operaciones/TI sus herramientas serían: checklist de incidente y bots.
1- Checklist de incidente
Esta es la herramienta principal que se usa para darle seguimiento a las tareas claves, por ejemplo podemos tener un checklist con estas tareas:
- Actualizar página de estado.
- Seleccionar encargado de comunicaciones.
- Planear failover a sitio de contigencia.
- Asegurar que todos estén trabajando en lo mismo.
Este checklist debe estar a mano del comandante del incidente desde que inicia hasta que termina.
2- Bots
En TI tenemos la suerte de contar con herramientas como incident-bots en Slack que permiten crear y asignar muchas tareas con un solo comando como (/incident task @ops-oncall Falla de healthcheck en servicio de pagos) con bots de este tipo podemos crear checklists compartidos y evitar que los pasos sean olvidados.
Herramienta opcional: Checklist Memory Items
En el mundo de la aviación existe el concepto de "Checklist Memory Items", estas son tareas que se deben ejecutar de memoria en caso de incidentes, están fuera de los checklists ya que las situaciones en las que se deben ejecutar requieren que se lleven a cabo con la mayor urgencia posible y cuando el hecho de tener que mirar un checklist de incidente tomaría demasiado tiempo, normalmente estos "memory items" se aplican en casos como:
- Ocurre un evento de "Stick Shaker" donde el mando empieza a vibrar lo que significa que el avión no tiene la velocidad suficiente para seguir en el aire, en respuesta a esto el piloto debe apuntar la nariz del avión hacia abajo inmediatamente.
- Aparece una alarma de fuego en un motor, aquí el piloto debe apagar inmediatamente el mismo y activar los sistemas antiincendios de memoria.
Como en el mundo de la informática es mucho más heterogéneo que el de la aviación, es difícil encontrar "memory items" que deban ser ejecutados de memoria en casos de incidentes, sin embargo el hecho de tener un par de tareas que deban ser ejecutadas de memoria por los miembros del equipo durante un incidente puede ser una herramienta muy útil, como ejemplo podríamos tener los siguientes "memory items" en TI:
- Activar un monitor más profundo que nos trae información mucho más detallada del estado de un servidor en particular.
- Hacer un "ping" a todos los miembros del equipo a través de Slack o Temas para que estén atentos.
- Poner en marcha el sitio de contigencia en caso de que requiera un cold-start.
- Correr un script que baje automáticamente servicios poco prioritarios del clúster.
Los memory items que incluimos tienen una particularidad, a diferencia de los de aviación que pueden causar estragos al ser ejecutados sin necesidad, los nuestros (para TI) son más inofensivos, idempotentes y enfocados a obtener más información sobre el problema, es recomendable usar este criterio si queremos armar nuestros propios memory items seguros.
Otro criterio a tener en cuenta es que según estudios científicos el momento más oportuno de ejecutar los memory items es al comienzo del incidente, si quedan como parte de un checklist lo más probable es que no sean ejecutados a tiempo o directamente pasados por alto.
¿Cuándo usar PIOSEE?
No es necesario aplicar PIOSEE en cada ticket o tarea. Este modelo es ideal para:
- Incidentes graves (P1/P2).
- Releases críticos o hotfixes.
- Cambios en infraestructura.
- Runbooks operativos con decisiones condicionales.
PIOSEE puede usarse individualmente (para pensar con claridad) o en equipo (para alinear criterios durante un incidente).
Beneficios de usar PIOSEE más allá del incidente
Aparte de ser el marco que nos solucionó el incidente, que ya es un beneficio claro, este también nos puede servir en el futuro.
Luego de cada incidente se debería iniciar un postmortem, si seguimos y documentamos el modelo PIOSEE durante el mismo ya tendremos prácticamente listo el postmortem y con estas ventajas:
- Consistente ya que todas las decisiones se tomaron con el mismo proceso.
- Claro ya que nos ayudó a distinguir los síntomas de los problemas reales.
- Justificado ya que las decisiones no se tomaron basadas en opiniones ni jerarquías.
Ejemplo de incidente manejado con PIOSEE
Escenario: Empezaron a llegar alertas del microservicio payments-api en producción.
Respuesta del equipo usando PIOSEE:
- Problema: Jefe de operaciones comenta a el equipo de desarrollo el problema y pregunta sobre el estado del microservicio, se ven picos de CPU afectando la latencia del servicio payments-api y desarrollo comenta que se hizo un despliegue hace 15 minutos.
- Información: Despliegue hecho hace 15 min. Ningún otro cambio. El contenedor payments-api al 95% de CPU. Otros servicios normales según el NOC.
- Opciones: Luego de pedir la opinión del equipo de desarrollo y operaciones anota las siguientes opciones:
- Hacer rollback del despliegue.
- Escalar los pods manualmente.
- Aumentar límites de CPU en el HPA.
- Revertir la imagen solo en nodos de alto tráfico.
- Seleccionar: Escalar los pods al doble. Más seguro y rápido que un rollback, justifica la elección a todos los equipos y estos le dan el OK y quedan atentos, anota la decisión en la bitácora del incidente.
- Ejecutar: Pide al equipo de SRE que aplique el cambio. Pide a un miembro del equipo del NOC que haga un monitoreo exclusivo a las métricas del microservicio afectado.
- Evaluar: CPU baja al 50%, latencia normalizada, pide al equipo de desarrollo y al jefe del producto que hagan una prueba exhaustiva del servicio. Incidente resuelto. Luego se encuentra que el problema era un bucle mal optimizado en el nuevo código.
En este caso el uso de PIOSEE dio orden a una situación caótica y permitió resolverla con calma. Aquí el jefe de operaciones aplicó las buenas prácticas de:
- Pedir opiniones.
- Delegar tareas y responsabilidades a otras áreas.
- Comunicar claramente el problema a todos los actores.
- No sacar conclusiones apresuradas sin antes tener respaldo de datos reales.
Conclusión
PIOSEE no nos dice qué decisión tomar. Pero nos ayuda a tomar mejores decisiones.
Destacamos la frase anterior porque en ningún momento habla de la naturaleza de las decisiones, no se limita a la aviación o la informática, al contrario, es un marco que puede ser aplicado a cualquier situación que requiera tomar una decisión bajo presión, sea a nivel profesional o personal, y al no ser un proceso que solo vive en la teoría, ya que es utilizada en una de las áreas más críticas que puede incluir a los humanos, es un proceso bien probado que vale la pena tenerlo anotado para sacarlo en situaciones difíciles.
Como reflexión final, la próxima vez que vueles piensa en qué tipos de pilotos te gustaría tener al mando de tu avión, seguro que desearás tener a los más experimentados y actualizados del área, a esos que manejan los procedimientos y con entrenamiento para lidiar con calma cualquier situación de emergencia. Ahora traslada este escenario al área de operaciones de tu sistema crítico, el deseo será el mismo, ya que por detrás de un avión que cuesta 100 millones de dólares y el área de TI de una empresa que vale lo mismo, siempre serán humanos los que determinen el desenlace final en momentos críticos.
Fuentes:
NASA – Toma de decisiones en aviación
SRE Playbook – Respuesta a incidentes
Checklist Memory Items - Efectos del estrés en la memoria humana