Trazabilidad en procesos financieros


Uno de los requisitos más importantes de los sistemas que manejan pagos electrónicos masivos es poder individualizar una transacción en particular y obtener estas informaciones:
- Información interna de la transacción, por ejemplo, el monto de un pago.
- Pasos y componentes que fueron necesarios para su ejecución.
- Tiempo que se tardó en cada paso.
- Si hubo un error, el lugar donde ocurrió y la razón.
Esta información solo será útil si cumple estas características:
- Precisa.
- Relevante.
- Completa.
- Actualizada.
- Objetiva.
- Consistente.
- Clara.
En este blog describiremos cómo logramos estas características en un sistema bancario simple que procesa transacciones las cuales pasan por N microservicios y bases de datos para completarse.
El objetivo no es entrar en detalles de implementación sino más bien mostrar cómo unos ajustes (que individualmente son relativamente sencillos) a la forma de manejar logs pueden crear un cimiento muy robusto para el troubleshooting y la toma de decisiones.
Un sistema bancario simple
Como ejemplo tenemos un sistema bancario el cual procesa transacciones del tipo "transferencia" del usuario.
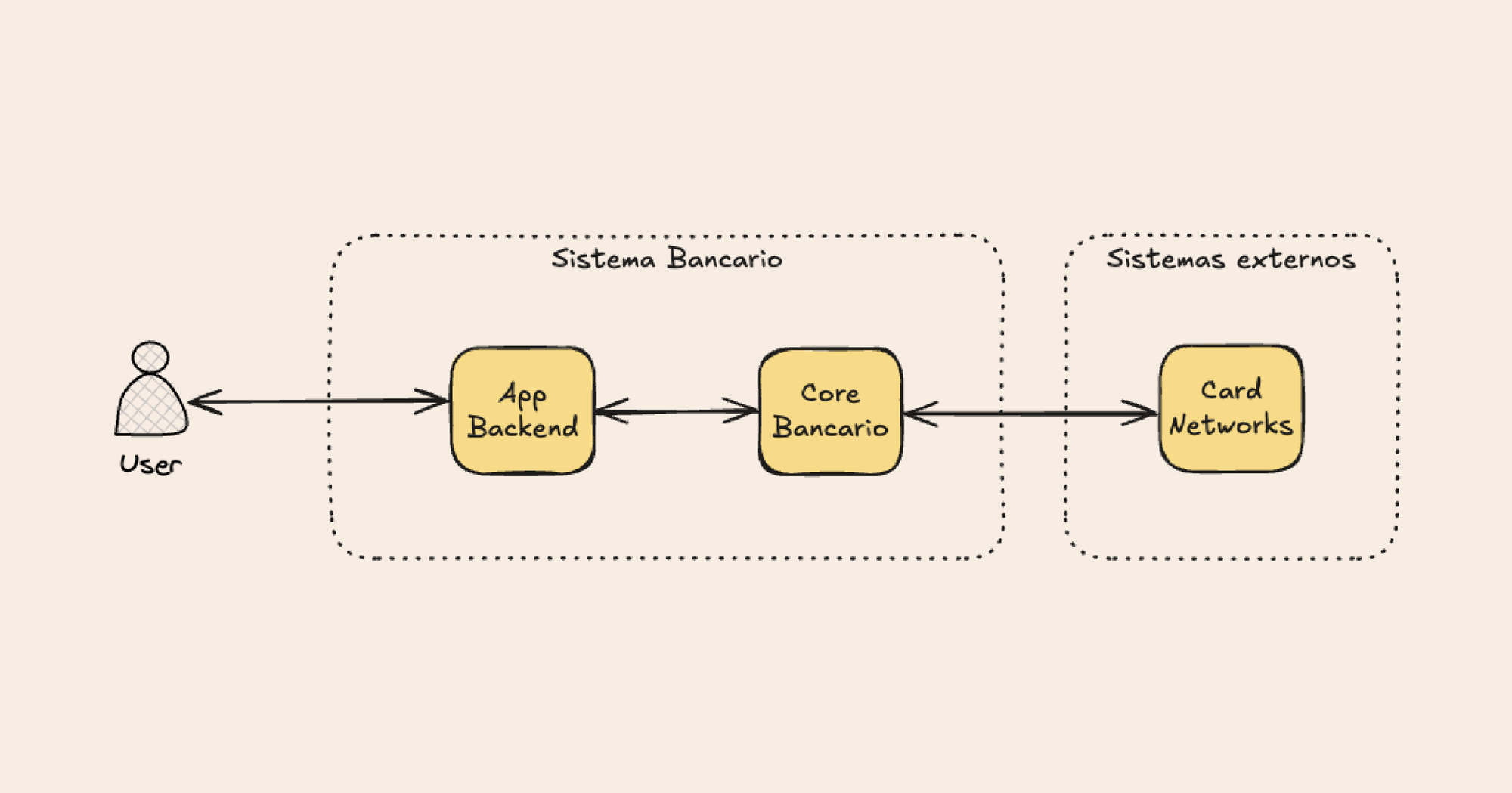
Esta arquitectura simplificada está compuesta por estos servicios:
- API Gateway
- Microservicio de autenticación
- Microservicio de transferencia
- Microservicios secundarios
- Base de datos
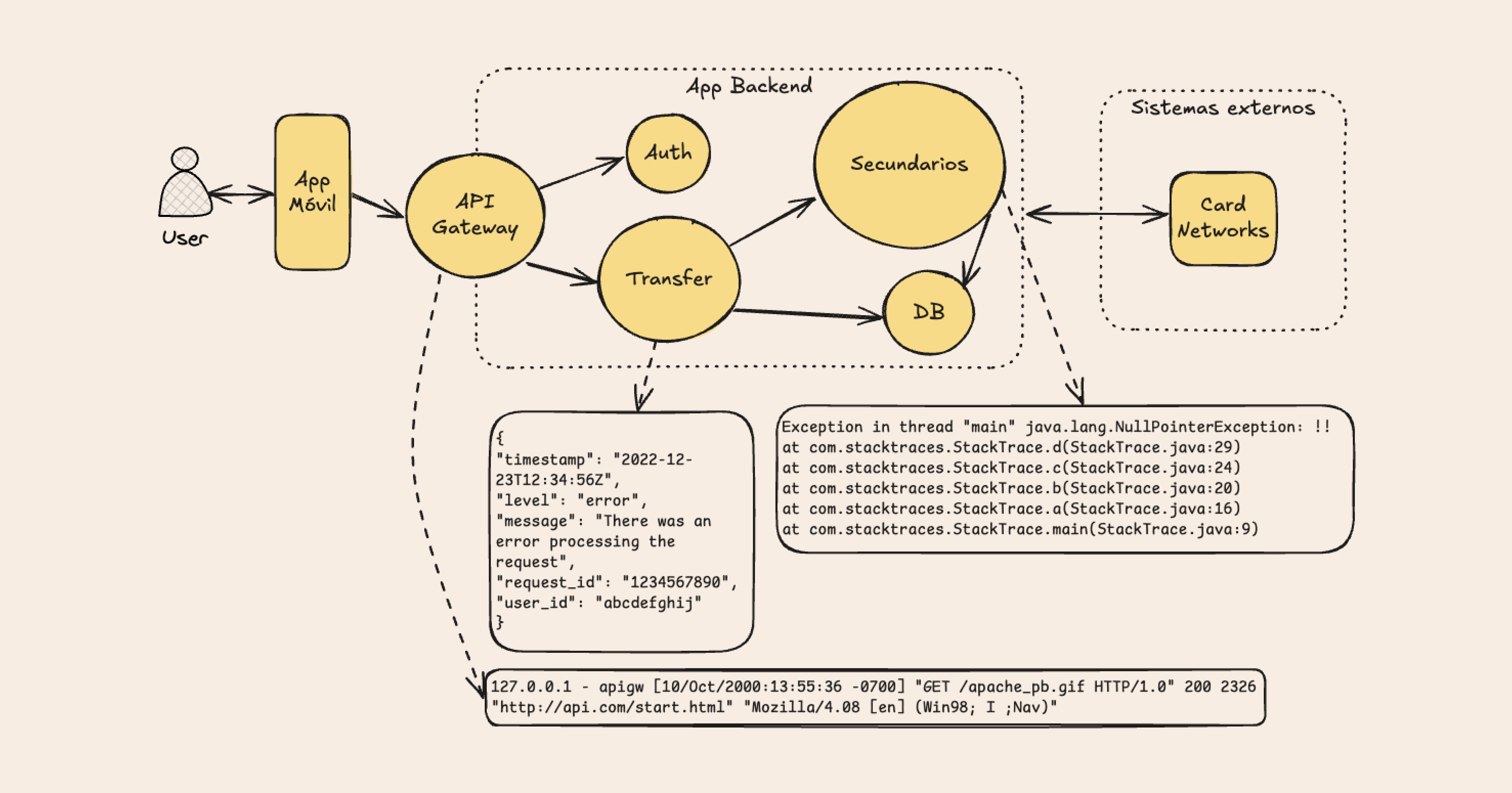
Estas transacciones siguen este flujo al llegar al sistema:
- El API Gateway redirige la petición al microservicio correcto y aplica ciertas restricciones como rate-limiting y filtros por IP.
- El microservicio de autenticación genera un token para el usuario.
- El usuario realiza una petición de transferencia, extracción o pago sobre una ruta específica incluyendo el token.
- El API Gateway redirige la petición al microservicio correcto.
- El microservicio correspondiente a la operación realiza los pasos necesarios para completarla, lo que incluye modificaciones en la base de datos y uso de otros microservicios secundarios como notificaciones.
- El microservicio responde al usuario el resultado de la operación.
Esta arquitectura, por más que sea simplificada, ya introduce una gran cantidad de oportunidades para que ocurran fallos, asumiendo que tenemos bien implementados los logs de nuestra aplicación (que no siempre ocurre) y es fácil accederlos (tampoco suele ocurrir), el análisis de un fallo de la transacción implicaría realizar estos pasos:
- Revisar la respuesta recibida por el usuario en el dispositivo.
- Revisar los logs del API Gateway.
- Revisar los logs del microservicio de transferencia.
- De ser necesario, explorar los logs de los microservicios secundarios.
- De ser necesario, explorar los logs de la base de datos.
Experiencias
Antes de listar los casos y mejoras, veamos un ejemplo de un log típico de un sistema:
2025-01-01 15:30:44.123 - INFO - AuthController - Intento de login del user 'admin'
2025-01-01 15:30:44.456 - WARN - AutoBlockService - Bloqueando usuario 'admin' por exceso de intentosEste contiene la siguiente información:
- Fecha y hora: en el timezone del servicio
- Level: bastante estandarizado, WARN, INFO, DEBUG, TRACE
- Componente: qué clase/componente produjo el log
- Mensaje: mensaje del log en sí
Aparte de estos campos, también se pueden incluir:
- trace-id: un identificador único de una operación o transacción en particular.
- Servicio: identificador del servicio o sistema que generó el log, útil en arquitecturas de microservicios.
Teniendo en cuenta las características deseables de la información que tenemos de la transacción, exploremos las mejoras que podemos introducir en base a situaciones y frases de la vida real con las que nos hemos encontrado:
Precisión
- "Encontramos los logs, pero el (trace-id o nombre de servicio) no coinciden y estamos casi seguros que se trata de la misma transacción"
2. "Puedo ver todo el stack trace en este log, pero en este otro solo veo la petición"
3. "Para el microservicio X en particular, se deben mirar los logs de hace 3 horas"
Estas 3 situaciones ocurren cuando nuestro ecosistema de logs no nos puede dar información precisa sobre lo que estamos buscando lo cual reduce su confiabilidad, las 3 estrategias para mejorar esta característica son:
- Asegurarnos que los logs de todos los servicios incluyan estos 3 campos:
- trace-id
- timestamp
- nombre del servicio
- Usar solo un formato de logs para todos los servicios, en nuestra experiencia, el mejor formato es JSON, ya que permite otras mejoras que veremos más adelante.
- Sincronizar relojes de todos los servicios con NTP o en el propio código, esto nos quita la carga mental de lidiar con sistemas con relojes diferentes, esto puede no ser posible por restricciones de sistemas externos, lo cual se mitiga creando otros campos de timestamp que se ajusten a nuestros sistemas.
Relevancia
- "Esta transacción genera 3 logs en este servicio, debemos encontrar el correcto y no tener en cuenta algunos campos"
- "Debemos leer e interpretar la respuesta para saber si se trata de un error"
- "Tenemos los logs del error, pero no sabemos donde empezó esta transacción"
Nos topamos con este tipo de problemas cuando nuestros logs contienen información poco útil sobre lo que estamos investigando, esto se soluciona si:
- Tenemos un sistema que nos permita filtrar los logs relevantes del caso que estamos investigando, por ejemplo, solo los de error.
- Usamos y estandarizamos niveles de log (INFO, DEBUG, ERROR) sobre todos los servicios para poder filtrarlos de acuerdo al escenario actual.
- Implementamos trace-id con parent-id, el primero nos dice a qué transacción corresponden los logs y el segundo el orden en que se ejecutaron.
Completitud
- "Sabemos que estos logs son de esta transacción ya que tienen los campos "monto" en este microservicio y el campo "envío_exitoso" en este otro"
- "Vemos la petición en este log y la respuesta en este otro, el commit de la base de datos lo vemos en su propio log".
Tener logs incompletos también reduce considerablemente la confiabilidad, esto lo podemos mitigar con estos cambios:
- Respetando la trazabilidad "end-to-end" mediante un trace-id único y global, con esto filtramos de forma sencilla los logs de una transacción en particular.
- Asegurándonos que todos los servicios generen logs en estos checkpoints importantes: al recibir un request, luego de validarlo, luego de procesarlo, al hacer un commit a la base de datos y al enviar la respuesta, con esto podemos ver la lista de pasos que siguió la transacción no solo entre sistemas sino en el propio código.
Actualizada en el tiempo
- "Tenemos los logs del API Gateway, los del servicio de transferencia lo envía el equipo de producción en 5 minutos"
- "Estamos filtrando los logs de la transacción con 'grep' sobre este archivo que contiene los logs de transacciones de la última hora"
- "La aplicación está respondiendo errores 500 mientras estamos investigando una lentitud reportada hace 30 minutos"
No tener logs actualizados nos roba tiempo muy valioso en casos de emergencias, los puntos a implementar para mejorar esta característica son:
- Agregación de logs en tiempo real (ELK, Datadog, Splunk) para poder consultar los logs en un solo lugar sin necesidad de esperar por otros equipos.
- uso de log streaming en vez de procesar logs en batch para reducir el lag a la hora de consultarlos.
- Alertas automatizadas para informar sobre anomalías a medida que van ocurriendo.
Objetividad
- "Los logs del incidente fueron sobreescritos o modificados durante el troubleshooting"
- "Este error suele ocurrir cuando el sistema X falla, deberíamos probar reiniciarlo para ver si se soluciona"
La objetividad de nuestro sistema depende de que la información que provee sea real y que la interpretemos de forma correcta, esto lo logramos con:
- Un sistema de logs inmutables, esto es normalmente requerido para certificaciones de seguridad, donde los logs o una copia de estos quedan en un sistema write-once.
- Una cultura de evitar interpretaciones u opiniones sobre logs, estos deberían ser utilizados como una evidencia más en la toma de decisiones y cada una de estas debería estar justificada.
Consistencia
- "Las alertas del incidente no se activaron, luego de una actualización cambió el esquema de logs"
El "format-drift" de logs es un fenómeno muy común especialmente en arquitecturas de microservicios que ocurre por más que ya se tenga un formato acordado y unificado, normalmente ocurre cuando pequeños cambios en el formato impactan a sistemas de alertas y de BI pasando desapercibidas.
Este problema solo se puede mitigar haciendo auditorías de logs periódicas que detecten y reporten a servicios que loguean de manera inconsistente.
Claridad
- "Costó encontrar el error ya que estaba enterrado en un stack trace"
- "La aplicación responde 200 con el código de error 500 un campo de la respuesta"
- "Estos logs solo nos dicen que falló el componente X pero no sabemos cómo se relacionan"
Logs poco claros son causa de: toma incorrecta de decisiones y pérdidas de tiempo, que podemos mejorar mediante:
- Uso de logs estructurados y human-readable, stack-traces raramente son necesarios en ambientes productivos.
- Asegurarse de que los logs contengan campos para códigos de error y descripciones consistentes en vez de mensajes de falla genéricos.
- Generar logs con metadatos útiles (ej. user ID, monto de transacción, método API) para simplificar el proceso de debugging.
Esquema ideal
Como vemos en la siguiente imagen, una vez implementadas la estandarización de formatos, centralización, campos útiles y alertas logramos que el sistema de logs se convierta en un asistente automatizado a la hora de hacer debugging.
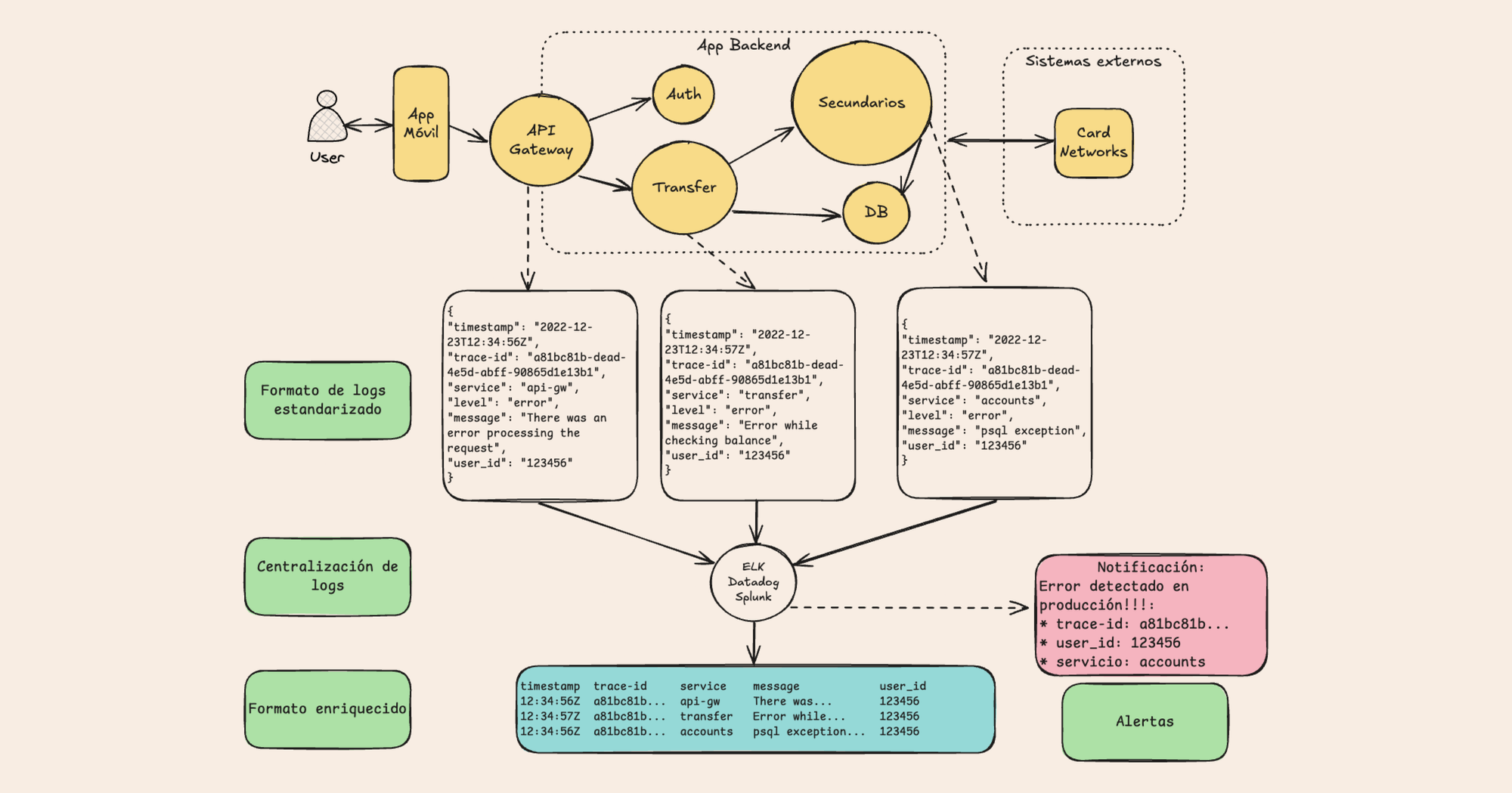
Este sistema puede ser extendido para lograr:
- Detección temprana de anomalías que aún no se convierten en problemas.
- Medir y mejorar el rendimiento del sistema incorporando métricas sobre las transacciones.
- Obtener insights de Business Intelligence.
Conclusión
La correcta gestión de logs en sistemas transaccionales no es solo una herramienta para debugging, sino una pieza fundamental para la estabilidad, seguridad y eficiencia operativa. Implementando buenas prácticas como trazabilidad end-to-end, logs estructurados, sincronización de tiempos y alertas automatizadas, podemos garantizar que nuestros sistemas no solo sean más fáciles de mantener, sino también más confiables y resistentes ante fallos.
Aunque cada sistema tiene sus particularidades, los principios descritos aquí pueden aplicarse a prácticamente cualquier arquitectura basada en microservicios. Con un enfoque proactivo y un ecosistema de logs bien diseñado, podemos reducir significativamente el tiempo de resolución de incidentes y tomar decisiones fundamentadas basadas en datos reales.